Az RDF/XML szintaxis
specifikációja
(Ez a fordítás a W3C Magyar Irodájának megbízásából,
az
Informatikai és Hírközlési Minisztérium
támogatásával készült)
- Az eredeti dokumentum:
- RDF/XML
Syntax Specification (Revised)
- http://www.w3.org/TR/2004/REC-rdf-syntax-grammar-20040210/
- A lefordított dokumentum:
- http://www.w3c.hu/forditasok/RDF/REC-rdf-syntax-grammar-20040210.html
- Magyar fordítás (Hungarian translation):
- Pataki, Ernő 2005 (pataki.erno@w3c.hu)
- A fordítás státusa:
- Kézirat. Lezárva: 2005.03.22.
Utoljára módosítva: 2005.04.25.
- Ez a fordítás a W3C engedélyével, a
fordításokra előírt formai szabályok szerint, lelkiismeretes
szakfordítói munkával készült. Ennek ellenére nem lehet kizárni, hogy
hibák maradtak a fordításban. Emellett a magyar fordítás nem is követi
feltétlenül az eredeti angol nyelvű dokumentumon végrehajtott jövőbeli
változtatásokat. Ezért a fordítás nem tekinthető normatív W3C
dokumentumnak. A dokumentum normatív, mindenkori legújabb,
hivatalos, angol nyelvű változatát lásd a W3C megfelelő weblapján: http://www.w3.org/TR/rdf-syntax-grammar/
- Megjegyzések a fordításhoz:
- 1.) A fordítással kapcsolatos olvasói észrevételeket a fordító e-mail
címére kérjük.
2.) A fordító a saját megjegyzéseit feltűnően elkülöníti a dokumentum
szövegében.
3.) A fordítással kapcsolatos további információkat, valamint a
terminológiai kérdések diszkusszióját lásd a Köszönetnyilvánítás és
megjegyzések a magyar fordításhoz c. mellékletben.
4.) A W3C Magyar Irodája a lehetőségek szerint lefordíttatja az OWL-ra
és az RDF-re vonatkozó W3C ajánlások legtöbb dokumentumát. Ha tehát egy
lefordított dokumentumból olyan OWL vagy RDF dokumentumra történik
hipertext-hivatkozás, mely magyar változatban is rendelkezésre áll,
akkor a megfelelő link általában a magyar változatra mutat. A kivételt
azok a hivatkozások képezik, amelyeknek a W3C szándékai szerint
mindenképpen az eredeti dokumentumra kell mutatniuk.
Az RDF (Resource Description Framework) egy keretrendszer a weben történő
információábrázolás céljára.
Ez a dokumentum egy XML szintaxist definiál
az RDF számára az XML névterek, az
XML Információhalmaz (XML Information
Set) és az XML Bázis (XML Base) fogalmai
alapján. Ezt a szintaxist RDF/XML-nek nevezzük. A szintaxis formális nyelvtanához olyan akciók vannak
csatolva, amelyek az RDF gráfok
tripletjeit generálják, ahogyan ezeket Az RDF alapfogalmai és absztrakt
szintaxisa című dokumentum definiálja. A tripleteket az N-Triples konvenció
szerinti gráfsorosító formátumban írjuk, mely egy pontosabb, géppel
feldolgozható leképezés rögzítését teszi lehetővé. A leképezést teszt-esetek
formájában adja meg a nyelvtan; ezeket Az RDF tesztsorozata című
dokumentum foglalja egybe.
Ezt a dokumentumot a W3C tagjai és más érdekelt résztvevők ellenőrizték,
és az Igazgató W3C
Ajánlásként hitelesítette. Az Ajánlás elkészítésével a W3C célja és
szerepe az, hogy ráirányítsa a figyelmet a specifikációra, és elősegítse
annak széles körű alkalmazását. Ez megnöveli a Web használhatóságát, és
javítja a weben történő együttműködést.
Ez a dokumentum egyike annak a hat
dokumentumnak (Bevezetés, Fogalmak, Szintaxis, Szemantika, Szókészlet és Tesztsorozat), amelyek együttesen
felváltják az eredeti Resource Description Framework specifikációkat: az RDF Model and
Syntax (1999 Recommendation) és az RDF Schema (2000
Candidate Recommendation) című dokumentumokat. A jelen dokumentumot az RDF Core Working Group (RDF-mag
Munkacsoport) dolgozta ki a W3C
Szemantikus Web Munkaprogramja keretében, és 2004. február 10. dátummal
publikálta. (Lásd a Munkaprogram-nyilatkozatot és a
Munkacsoport
alapszabályát).
Az Előzetes Ajánlástervezet munkaanyag óta a jelen Ajánlás
megszületéséig a dokumentumon végrehajtott módosításokat a változtatási napló részletezi.
A Munkacsoport szívesen fogadja az olvasóközönség észrevételeit a www-rdf-comments@w3.org (archive)
címén; az idevágó technológiák általános vitáját pedig a www-rdf-interest@w3.org (archive) címén folytatja.
Rendelkezésre áll egy konszignáció az ismert
alkalmazásokról.
A W3C listát vezet továbbá azokról a felfedett szabadalmi igényekről is, amelyek ehhez a
munkához kapcsolódnak.
Ez a szekció a dokumentumnak a publikáláskor érvényes státusát
rögzíti. Más dokumentumok hatálytalaníthatják ezt a dokumentumot. A legújabb
W3C publikációk listája, valamint e technikai riport utolsó kiadása
megtalálható a W3C technikai riportok
indexében, a http://www.w3.org/TR/ alatt.
Ez a dokumentum az RDF gráfok XML szintaxisát
definiálja, amelyet eredetileg az RDF Model &
Syntax - [RDF-MS] W3C ajánlás definiált. E
szintaxis egymást követő implementációinak tapasztalatai, valamint az általuk
kiadott RDF gráfok összehasonlításai azt mutatták, hogy némi inkonzisztencia
van a rendszerben, és bizonyos szintaxisformákat nem is implementáltak elég
széles körben a fejlesztők.
A jelen a dokumentum revízió alá veszi az eredeti
RDF/XML nyelvtant az XML
Információhalmaz ([INFOSET])
információtételei szempontjából, és ebben eltávolodik az XML meglehetősen
alacsony szintű részleteitől (mint pl. az üres elemek különböző formái). Ez
lehetővé teszi a nyelvtan pontosabb rögzítését, és az XML szintaxis RDF
gráfokra történő leképezésének világosabb bemutatását. Az RDF gráfokra
történő leképezés úgy történik, hogy az elemi kijelentéseket Az RDF Tesztsorozata [RDF-TESZTEK] című dokumentum által definiált N-Triples notációban adja
ki a nyelvtan, és így olyan gráfot állít elő, amelynek szemantikája megfelel
az [RDF-SZEMANTIKA] dokumentumban definiált
szemantikának.
Az RDF teljes specifikációja az alábbi dokumentumokból áll:
Egy hosszabb bevezetést tartalmaz az RDF/XML-hez (történeti
megvilágításban is) az RDF:
Understanding the Striped RDF/XML Syntax [STRIPEDRDF] dokumentum.
Ez a fejezet egy bevezetés az RDF/XML szintaxisba, mely leírja, és
példákon keresztül is illusztrálja, hogy hogyan történik az RDF gráfok
kódolása. Ha bármilyen ütközés fordulna elő ezen informális leírás és a 6. fejezet: A szintaxis adatmodell, vagy a 7. fejezet: RDF/XML Nyelvtan formális
leírása között, akkor mindig ez utóbbiak az irányadók.
"Az RDF alapfogalmai és absztrakt
szintaxisa" [RDF-FOGALMAK] dokumentum 3.1
szekciója definiálja az RDF gráf
adatmodellt, a 6. fejezete pedig az RDF Gráf absztrakt
szintaxisát. Ezek a részek "Az RDF
szemantikája" [RDF-SZEMANTIKA]
dokumentum anyagával együtt egy absztrakt szintaxist definiálnak, a hozzá
tartozó formális szemantikával együtt. Az RDF gráf csomópontokból, és
címkézett, irányított élekből áll, ahol az élek csomópont-párokat kötnek
össze. Ezt a gráfot RDF tripletek
halmazával ábrázoljuk, ahol minden tripletnek van egy
alany-csomópontja, egy állítmánya és egy
tárgy-csomópontja. A csomópontok RDF URI
hivatkozások, RDF
literálok vagy üres csomópontok lehetnek. Az üres csomópontoknak adhatunk
egy, csak a dokumentumon belül érvényes, nem RDF URI
hivatkozás jellegű, helyi nevet, amelyet ürescsomópont-azonosítónak
hívunk. Az állítmányok mindig RDF URI
hivatkozások, és felfoghatók két csomópont közötti viszonyként, vagy
olyan tulajdonságok definícióiként, amelyek az alany-csomóponthoz egy
tulajdonságértéket (tárgy-csomópontot) kapcsolnak.
Hogy XML-ben kódolhassuk a gráfot, a csomópontokat és az állítmányokat XML
kifejezésekkel – elemnevekkel, attribútum-nevekkel, elemtartalommal és
attribútum-értékekkel – kell ábrázolnunk. Az RDF/XML XML
minősített neveket (QNames)
használ az URI hivatkozások ábrázolására, ahogyan azt a Namespaces in
XML - [XML-NS] dokumentum definiálja.
Minden minősített név egy névtér-névből,
és egy rövid helyi
névből áll. A névtér-név, mely egy URI hivatkozás, helyettesíthető egy
rövidített prefixszel
is a minősített névben, vagy akár el is hagyható, amennyiben deklarálunk
számára egy alapértelmezett névtér-nevet (amelynek révén végül is lesz egy
névtér-név a hivatkozásban).
A minősített névvel ábrázolt RDF URI
hivatkozás úgy jön létre, hogy a név helyi
részét a névtér-név
végéhez illesztjük. Az ilyen neveket az állítmányok, valamint néhány
csomópont nevének a rövidítésére használjuk. Az alany- és tárgy-csomópontokat
azonosító RDF URI
hivatkozásokat XML attribútum-értékként is használhatjuk. Az RDF literálokat,
amelyek csak tárgy-csomópontok lehetnek, vagy XML elemek szöveges
tartalmaként, vagy XML attribútumok értékeként használhatjuk.
Egy gráf felfogható olyan útvonalak gyűjteményének is, amelyen váltakozva
jelenik meg egy csomópont, majd egy állítmány-él, majd ismét egy csomópont,
és így tovább, amíg le nem fedi a teljes gráfot. Az RDF/XML-ben ezek a
komponensek egymásba ágyazódó elemek sorozataként, váltakozva, hol
csomópontként, hol állítmány-élként jelennek meg, és ezért a gráfot leíró XML
kódot csomópont-él "csíkok" sorozatának is tekinthetjük. A sorozat elején
lévő csomópont lesz a legkülső szülő elem, a következő állítmány-él a gyermek
elem és így tovább. A csíkok sorozata általában az XML dokumentum elején
indul, és mindig csomóponttal kezdődik.
A következő szekciókban több olyan RDF/XML példát is bemutatunk, amelyek
komplett RDF/XML dokumentumot építenek fel (a 7.
példa lesz az első komplett RDF/XML dokumentum). Az 1.
ábrán bemutatott gráf, történetesen, a jelen dokumentum
(rdf-syntax-grammar) néhány tulajdonságát írja le: a dokumentum
címét (title), a szerkesztőjét (editor), a szerkesztő nevét
(Name) és a szerkesztő honlapját (homePage):
Az 1. ábrán egy RDF gráfot adtunk meg, ahol a
csomópontokat oválisok ábrázolják, amelyek saját RDF URI
hivatkozásaikat tartalmazzák (már ahol vannak ilyenek); az
állítmány-éleket szintén azok RDF URI
hivatkozásaival címkézzük; a típus nélküli
literálok csomópontjait pedig dobozok szimbolizálják, ezekben a literálok
értékeit tüntetjük fel.
A 2. ábrán kövessük végig az egyik
csomópont-él-csomópont... útvonalat:
A 2. ábra bal oldalán végigfutó gráf megfelel az
alábbi csomópont/állítmány-él csíkozásnak:
- Csomópont egy RDF URI
hivatkozással:
http://www.w3.org/TR/rdf-syntax-grammar
- Állítmány-él egy RDF URI
hivatkozással címkézve:
http://example.org/terms/editor
- Csomópont RDF URI
hivatkozás nélkül
- Állítmány-él egy RDF URI
hivatkozással címkézve:
http://example.org/terms/homePage
- Csomópont egy RDF URI
hivatkozással
:
//purl.org/net/dajobe/
A 2. ábra bal oldalán látható 5 gráfkomponens az
RDF/XML kódban megfelel öt, egymásba ágyazott XML elemnek, amelyek két típusa
(gráf csomópont és állítmány-él) váltakozva fordul elő. Ezeket
konvencionálisan csomópont-elemeknek, illetve tulajdonságelemeknek nevezzük.
Az 1. példában látható csíkozásában az
rdf:Description a csomópont-elem (amelyet három alkalommal
használtunk a három csomópontnak megfelelően), az ex:editor és
az ex:homePage pedig a két tulajdonságelem.
<rdf:Description>
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description>
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
A 2. ábrán látható gráfban két olyan csomópont van,
amelyek RDF URI
hivatkozások. Ezeket a hivatkozásokat RDF/XML-ben az
rdf:about attribútum segítségével rendeljük a
csomópont-elemekhez, s így a 2. példában látható
eredményt kapjuk:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
Ha az 1. ábrán látható gráf másik két útvonalát
hozzáadnánk a 2. példában szereplő RDF/XML kódhoz,
akkor ez a 3. példa által bemutatott ábrázolást
eredményezné. (Az ex:fullName tulajdonság jelentése: "teljes
neve". Ezen a példán most nem ábrázoltuk, hogy az üres csomópont közös a két
útvonal számára – lásd a 2.10-nél):
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
</rdf:Description>
</ex:editor>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
</rdf:Description>
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
Több olyan rövidítési lehetőség van, amellyel megkönnyíthetjük a
leggyakrabban előforduló RDF/XML szerkezetek leírását. Különösen gyakori
például, hogy az RDF gráfban az alany-csomópontból több állítmány-él fut ki.
Ilyen esetekben, vagyis ahol egy erőforrás-elemnek több tulajdonságeleme van,
az RDF/XML egy rövidítési lehetőséget biztosít a szintaxis leírásánál. Ennek
lényege, hogy az alany-csomópontot leíró szülő-elembe több gyermek-elemet
építhetünk be.
Vegyük a 3. példát: itt két csomópont-elem van,
mely több tulajdonságelemet kaphat. A
http://www.w3.org/TR/rdf-syntax-grammar URI hivatkozással
azonosított alany-csomópont tulajdonságelemei az ex:editor és az
ex:title, az üres csomópont-elem tulajdonságelemei pedig az
ex:homePage és az ex:fullName. Ennek a rövidítésnek
az eredményét a 4. példa mutatja (szemben a 3. példával, itt most már az is látható, hogy csak
egyetlen üres csomópont van):
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage>
<rdf:Description rdf:about="http://purl.org/net/dajobe/">
</rdf:Description>
</ex:homePage>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
Amikor egy RDF gráfban egy állítmány-él olyan tárgy-csomópontra mutat,
amelynek nincsenek további állítmány-élei, és amely úgy jelenik meg
RDF/XML-ben mint egy üres csomópont-elem:
(<rdf:Description rdf:about="...">
</rdf:Description>, vagy <rdf:Description
rdf:about="..." />), akkor ez a szerkezet lerövidíthető. A
rövidítés úgy történik, hogy az üres tárgyleíró (rdf:Description) elemet
kihagyjuk a tulajdonságelemből, és helyette egy rdf:resource XML
attribútumot adunk neki, amelynek értéke a végződő tárgy-csomópont RDF URI
hivatkozása lesz.
A 4. példában még az ex:homePage
tulajdonságelem egy üres csomópont-elemet tartalmazott, amelyet egy
rdf:Description elem írt le, és amelynek az RDF URI
hivatkozása http://purl.org/net/dajobe/ volt. Ez a szerkezet
helyettesíthető egyetlen üres tulajdonságelemmel, és így az 5. ábrán látható RDF/XML kódhoz jutunk (itt az
ex:fullName tulajdonság jelentése: "teljes neve"):
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<ex:editor>
<rdf:Description>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
<ex:fullName>Dave Beckett</ex:fullName>
</rdf:Description>
</ex:editor>
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
Amikor egy tulajdonságelem tartalma egy karakterlánc típusú literál, akkor
ezt XML attribútumként is megadhatjuk a tulajdonságelemet tartalmazó
csomópont-elemben. Ezt megtehetjük több olyan tulajdonsággal is, amelyik
ugyanarra a csomópont-elemre vonatkozik, feltéve, hogy a
tulajdonságelem-nevek nem ismétlődnek (ezt az XML követeli meg, ugyanis az
ilyen neveknek egy adott elemen belül egyedieknek kell lenniük), és feltéve,
hogy a tulajdonságelemek karakterlánc literáljának minden szkópban lévő
xml:lang attribútuma (ha van ilyen) azonos nyelvet nevez meg
(lásd a 2.7 szekcióban). Ezt a
rövidítést tulajdonság-attribútumnak (property attribute) nevezzük,
és minden csomópont-elemben használható.
Ez a rövidítési forma akkor is használható, ha a tulajdonságelem
rdf:type, és van egy olyan rdf:resource
attribútuma, amelynek értéke egy RDF URI
hivatkozás típusú tárgy-csomópont.
Az 5. példában két tulajdonságelem (a
dc:title és az ex:fullName) rendelkezik
karakterlánc literál tartalommal. Ezeket helyettesíthetjük
tulajdonság-attribútumokkal, és így a 6. példában
szereplő kódot kapjuk eredményül:
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</rdf:Description>
</ex:editor>
</rdf:Description>
Hogy egy teljes RDF/XML dokumentumot alakíthassunk ki, a gráf XML-lé
történő átalakítását (sorosítását vagy szerializációját) általában az
rdf:RDF nevű XML elemen belül írjuk le, mely a legkülső szintű
eleme lesz a dokumentumnak. Konvenció szerint, az rdf:RDF elemet
az alkalmazott XML névterek deklarálására is felhasználjuk, habár ez nem
kötelező. Ha csak egyetlen csúcs szintű elem lenne az rdf:RDF
elemen belül, akkor az rdf:RDF elem elhagyható, ám az XML
névtereket ilyenkor is deklarálnunk kell.
Az XML specifikáció megenged egy XML deklarációt is a dokumentum
legelején, mely jelezheti az XML verzióját, és esetleg az XML tartalom
kódolását. Ez egy opcionális, de ajánlott elem.
Az RDF/XML kód teljes dokumentummá történő kiegészítése elvégezhető
bármelyik korrekt és komplett gráfpéldánál, a 4.
példától felfelé. Ha vesszük a legrövidebbet, a 6.
példát, és megadjuk hozzá a befejező komponenseket, akkor az eredeti 1. ábra teljes RDF/XML változatát kapjuk eredményül,
ahogyan a 7. példa mutatja:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor>
<rdf:Description ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/" />
</rdf:Description>
</ex:editor>
</rdf:Description>
</rdf:RDF>
A 7. példában nyugodtan kihagyhattuk volna az
rdf:RDF elemet, minthogy csupán egyetlen legkülső szintű
rdf:Description elem van az rdf:RDF tegpárok
között, de ezt itt most nem kívántuk illusztrálni.
Az RDF/XML megengedi az xml:lang nyelv-azonosító attribútum
használatát, ahogyan azt az XML 1.0 ([XML]) dokumentum 2.12 Language
Identification szekciója definiálja, annak érdekében hogy azonosítani
tudjuk az XML tartalom nyelvét. Az xml:lang attribútum
használható bármelyik csomópont-elemben vagy tulajdonságelemben annak
megjelölésére, hogy a benne foglalt tartalom nyelve az attribútummal megadott
nyelv. Azokat a tipizált
literálokat, amelyek XML-literálokat tartalmaznak, nem
érinti ez az attribútum. A legspecifikusabb, szkópban lévő nyelvet (ha van
ilyen megadva), a tulajdonságelemek karakterlánc típusú literáljaira, vagy
tulajdonság-attribútumainak értékére alkalmazzuk. Az xml:lang=""
forma jelzi, ha az adott szkópban lévő tartalomra nincs megadva
nyelv-azonosító.
Az RDF tulajdonságok tartalomleíró nyelvének megjelölését mutatja be a 8. példa:
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar">
<dc:title>RDF/XML Syntax Specification (Revised)</dc:title>
<dc:title xml:lang="en">RDF/XML Syntax Specification (Revised)</dc:title>
<dc:title xml:lang="en-US">RDF/XML Syntax Specification (Revised)</dc:title>
</rdf:Description>
<rdf:Description rdf:about="http://example.org/buecher/baum" xml:lang="de">
<dc:title>Der Baum</dc:title>
<dc:description>Das Buch ist außergewöhnlich</dc:description>
<dc:title xml:lang="en">The Tree</dc:title>
</rdf:Description>
</rdf:RDF>
Az RDF lehetővé teszi XML-literálok megadását állítmányok
tárgy-csomópontjaként. (Lásd: [RDF-FOGALMAK]
- XML-literálok
5.1: XML tartalom az RDF gráfon belül). Ezeket úgy adjuk meg RDF/XML-ben,
mint a tulajdonságelem tartalmát (tehát nem, mint egy tulajdonság-attribútum
értékét), és egy rdf:parseType="Literal" attribútummal jelöljük
meg az XML tartalmat befogadó tulajdonságelemben.
Egy XML-literál írását mutatja be a 9. példa, ahol
egyetlen triplet van megadva egy alany-csomóponttal (RDF URI
hivatkozása: http://example.org/item01), egy állítmánnyal
(RDF URI
hivatkozása: http://example.org/stuff/1.0/prop – az
ex:prop névből generálva), valamint egy tárgy-csomóponttal,
amelyben az XML-literál tartalma az a:Box tegpárok között
helyezkedik el:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/item01">
<ex:prop rdf:parseType="Literal"
xmlns:a="http://example.org/a#"><a:Box required="true">
<a:widget size="10" />
<a:grommit id="23" /></a:Box>
</ex:prop>
</rdf:Description>
</rdf:RDF>
Az RDF lehetővé teszi tipizált
literálok megadását is állítmányok tárgy-csomópontjaként. A tipizált
literál egy literál karakterláncból és egy adattípusra mutató RDF URI
hivatkozásból áll. Ezt RDF/XML-ben ugyanazzal a szintaxissal adjuk meg,
mint a literálkarakterlánc-csomópontot a tulajdonságelemen belül (tehát nem
egy tulajdonság-attribútumban), de kibővítve még egy
rdf:datatype="datatypeURI" attribútummal
is, ahol bármilyen RDF URI
hivatkozás állhat az idézőjelek között.
Egy RDF tipizált literál
írását mutatjuk be a 10. ábrán, ahol egyetlen
triplet szerepel egy alany-csomópont elemmel (RDF URI hivatkozása:
http://example.org/item01), egy állítmánnyal (RDF UR hivatkozása:
http://example.org/stuff/1.0/size – az
ex:size névből generálva), valamint egy tárgy-csomóponttal, mely
egy tipizált
literált tartalmaz ("123",
http://www.w3.org/2001/XMLSchema#int), és amelyet egész szám
(int) adattípusnak kell értelmezni a W3C XML Schema
- [XML-SCHEMA2] specifikáció szerint.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/item01">
<ex:size rdf:datatype="http://www.w3.org/2001/XMLSchema#int">123</ex:size>
</rdf:Description>
</rdf:RDF>
Az RDF gráfokban az üres csomópontok
megkülönböztethetők a többi csomóponttól, bár nem RDF URI
hivatkozással azonosítjuk őket. Néha szükséges, hogy a gráfnak ugyanarra
az üres csomópontjára az RDF/XML kód több helyéről is hivatkozhassunk (pl.,
amikor ez a csomópont több RDF tripletnek is alanya vagy tárgya). Ilyenkor
egy ún. ürescsomópont-azonosítót
adhatunk az üres
csomópontnak, hogy egyértelműen azonosíthassuk a dokumentumon belül.
Ezeknek az azonosítóknak tehát csak az őket tartalmazó XML információhalmaz
(XML infoset) dokumentum információtételén (document
information item) belül kell egyedieknek lenniük. Az ürescsomópont-azonosítót
egy csomópont-elemben az rdf:about="RDF URI
hivatkozás" attribútum helyettesítésére, egy
tulajdonság-elemen belül pedig az rdf:resource="RDF URI
hivatkozás" attribútum helyettesítésére használjuk, és
mindkét esetben az rdf:nodeID="ürescsomópont-azonosító"
attribútummal váltjuk fel őket.
Ha vesszük a 7. példát, és a benne szereplő üres
csomópontnak explicit módon, "abc" néven, adunk egy ürescsomópont-azonosítót,
akkor a 11. példában látható kódot kapjuk (a második
rdf:Description elem írja le az üres csomópontot):
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor rdf:nodeID="abc"/>
</rdf:Description>
<rdf:Description rdf:nodeID="abc"
ex:fullName="Dave Beckett">
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</rdf:Description>
</rdf:RDF>
Az RDF gráfokban az üres csomópontokat
(de nem az RDF URI
hivatkozásokkal azonosított csomópontokat) írhatjuk olyan formában is,
mely lehetővé teszi az <rdf:Description>
</rdf:Description> pár kihagyását. Ez úgy történik, hogy
egy rdf:parseType="Resource" attribútumot adunk meg az üres
csomópontot tartalmazó tulajdonságelemben, és ezáltal azt egy
tulajdonság-és-csomópont elemmé változtatjuk (amely maga is rendelkezhet mind
tulajdonságelemekkel, mind tulajdonság-attribútumokkal).
Tulajdonság-attribútumok és az rdf:nodeID nincs engedélyezve a
tulajdonság-és-csomópont elemekre.
Ismét a 7. példából kiindulva, az
ex:editor tulajdonságelem is írható ilyen alternatív módon, hogy
végül a 12. példában szereplő megoldást kapjuk:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor rdf:parseType="Resource">
<ex:fullName>Dave Beckett</ex:fullName>
<ex:homePage rdf:resource="http://purl.org/net/dajobe/"/>
</ex:editor>
</rdf:Description>
</rdf:RDF>
Ha egy üres csomópont-elemben megadott összes tulajdonságelemnek
karakterlánc típusú literális értéke van, ugyanazzal az xml:lang
értékkel (ha meg van adva egy ilyen az adott szkópban), és ha minden ilyen
tulajdonságelem csak egyszer fordul elő, továbbá ha legfeljebb egy
rdf:type tulajdonságelem szerepel benne egy RDF URI
hivatkozás típusú tárgy-csomóponttal mint értékkel, akkor ezek
lerövidíthetők oly módon, hogy tulajdonság-attribútumokká alakítjuk őket a
befogadó tulajdonságelemben, amelyet ezután üres elemmé alakítunk.
Térjünk vissza az 5. példához, ahol az
ex:editor elem egy üres csomópont-elemet tartalmaz két
tulajdonságelemmel: ex:fullname és ex:homePage. (Az
ex:homePage nem alkalmas az ilyen rövidítésre, mivel nincs
karakterlánc-literál típusú értéke, ezt tehát figyelmen kívül hagyjuk a
jelenlegi példánk szempontjából.) A rövidített forma eléréséhez eltávolítjuk
az ex:fullName tulajdonságelemet, és egy új
ex:fullName tulajdonság-attribútumot adunk meg az
ex:editor tulajdonságnak, egy olyan karakterlánc értékkel, mely
az imént törölt tulajdonságelem értéke volt. Az üres csomópont-elem így
implicitté válik a most már üres ex:editor tulajdonságelemben.
Az eredményt a 13. ábra mutatja:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://www.w3.org/TR/rdf-syntax-grammar"
dc:title="RDF/XML Syntax Specification (Revised)">
<ex:editor ex:fullName="Dave Beckett" />
<!-- Note the ex:homePage property has been ignored for this example -->
</rdf:Description>
</rdf:RDF>
Nagyon gyakori az RDF gráfokban, hogy alany-csomópontokra
rdf:type állítmányt adunk meg. Konvenció szerint, az ilyen
csomópontokat a gráfban tipizált csomópontoknak, az RDF/XML-ben
pedig tipizált csomópont-elemeknek hívjuk. Az RDF/XML lehetővé
teszi, hogy az ilyen tripleteket tömörebben fogalmazhassuk meg, oly módon,
hogy az rdf:Description csomópont-elem nevét helyettesítjük
azzal a minősített névvel, mely a "típusa" (type) viszony értékét jelentő RDF URI
hivatkozással azonos. Természetesen, lehet egy alanynak több
rdf:type állítmánya, de ezek közül csak egy rövidíthető ezzel a
módszerrel, a többi pedig változatlanul megmarad tulajdonságelemként vagy
tulajdonság-attribútumként a tipizált csomópont-elemben.
A tipizált csomópont-elemeket gyakran használjuk RDF/XML-ben az RDF szókészlet ilyen beépített osztályaival
kapcsolatban, mint: rdf:Seq, rdf:Bag,
rdf:Alt, rdf:Statement, rdf:Property
és rdf:List.
Példaképpen bemutatjuk, hogy miként rövidíthetjük le RDF/XML-ben a 14. példa kódját tipizált csomópont-elem
alkalmazásával. Az eredményt a 15. példa mutatja:
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/thing">
<rdf:type rdf:resource="http://example.org/stuff/1.0/Document"/>
<dc:title>A marvelous thing</dc:title>
</rdf:Description>
</rdf:RDF>
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:ex="http://example.org/stuff/1.0/">
<ex:Document rdf:about="http://example.org/thing">
<dc:title>A marvelous thing</dc:title>
</ex:Document>
</rdf:RDF>
Az RDF/XML lehetővé teszi az XML attribútumokban megadott RDF URI
hivatkozások további rövidítését, mégpedig kétféle módon. Az XML
információhalmaza (XML Infoset)
tartalmazza az xml:base attribútumot, mely deklarálja a
dokumentum bázis-URI-jét, amelyet az XML a relatív RDF URI
hivatkozások abszolúttá alakítására használ. (Ha ez az attribútum nincs
explicit módon megadva, akkor az implicit bázis-URI mindig az aktuális
dokumentum URI-je lesz). A bázis URI minden olyan RDF/XML attribútumra
érvényes, amelyben RDF URI
hivatkozásokat adhatunk meg; ezek a következők: rdf:about,
rdf:resource, rdf:ID és
rdf:datatype.
Az rdf:ID attribútum az rdf:about attribútum
helyett használható egy csomóponti elemben (sohasem egy tulajdonságelemben,
amelynek egészen más a jelentése), és arra szolgál, hogy megadjon egy relatív
RDF URI
hivatkozást, ami azonos egy '#' karakter és az rdf:ID
attribútum értékének az egybetoldásával. Így például, ha azt írjuk, hogy
rdf:ID="name", akkor az megfelel az
rdf:about="#name" hivatkozásnak. Emellett az rdf:ID
egy ellenőrzést is végez, annak megakadályozására, hogy egynél többször
deklaráljuk ugyanazt a relatív nevet ugyanazon a xml:base
látókörön (szkópon) belül (vagy, ha nincs explicit bázis megadva, akkor
ugyanazon az aktuális dokumentumon belül). Ez tehát egy hasznos segédeszköz
arra, hogy egymással összefüggő, de mégis megkülönböztethető helyi relatív
neveket használhassunk ugyanahhoz a bázis RDF URI
hivatkozáshoz képest.
Amint láthattuk, mindkét hivatkozás rövidítő forma arra épül, hogy adva
van egy bázis URI, akár egy szkópban lévő xml:base deklaráció
révén, akár az aktuális dokumentum implicit bázis-URI-je formájában.
A 16. példa bemutatja, hogy miként rövidítjük az
rdf:Description elemben a
http://example.org/here/#snack csomópont abszolút RDF URI
hivatkozását a http://example.org/here/ bázis URI mint
xml:base, valamint egy rdf:ID attribútum
segítségével. Az ex:prop állítmány tárgy-csomópontja is egy
rövidített RDF URI
hivatkozás, amely az rdf:resource attribútum értéke,
valamint az adott xml:base értéke alapján a
http://example.org/here/fruit/apple abszolút RDF URI
hivatkozásnak felel meg.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/"
xml:base="http://example.org/here/">
<rdf:Description rdf:ID="snack">
<ex:prop rdf:resource="fruit/apple"/>
</rdf:Description>
</rdf:RDF>
Az RDF definiál egy sor konténertagság-tulajdonságot, és az ezeknek
megfelelő tulajdonságelemeket, amelyeket leginkább ilyen konténerosztályok
tagjainak a megadására használunk, mint rdf:Seq,
rdf:Bag és rdf:Alt (Sorozat, Zsák és
Alternatíva-csoport). Az ilyen konténerosztályokat tipizált
csomópont-elemként is kódolhatjuk RDF/XML-ben. A
konténertagság-tulajdonságokat (rdf:_1, rdf:_2
stb.) tulajdonságelemekként és tulajdonság-attribútumokként egyaránt
írhatjuk, ahogy a 17. ábrán látható. Létezik egy
rdf:li nevű speciális tulajdonságelem is, mely ekvivalens az
rdf:_1, rdf:_2 ... tulajdonságokkal; ezt a 7.4 szekció ismerteti részletesebben. Az
rdf:li listaelem-tulajdonságoknak a megfelelő
konténertagság-tulajdonságokra történő leképezése abban a sorrendben
történik, amely sorrendben az rdf:li elemek megjelennek az XML
kódban – itt a dokumentumok sorrendje is szignifikáns. A 17. példának megfelelő RDF/XML kód, amelyet ilyen
formában írtunk meg, a 18. példában látható.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:_1 rdf:resource="http://example.org/banana"/>
<rdf:_2 rdf:resource="http://example.org/apple"/>
<rdf:_3 rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Seq rdf:about="http://example.org/favourite-fruit">
<rdf:li rdf:resource="http://example.org/banana"/>
<rdf:li rdf:resource="http://example.org/apple"/>
<rdf:li rdf:resource="http://example.org/pear"/>
</rdf:Seq>
</rdf:RDF>
Az RDF/XML lehetővé teszi, hogy egy
rdf:parseType="Collection" attribútum segítségével több
csomópont-elemet építhessünk be egy tulajdonságelembe. Ezek a beépített
csomópont-elemek a kollekció alany-csomópontjainak gyűjteményét alkotják. Ez
a szintaxisforma megfelel a tripletek egy olyan halmazának, amely
alany-csomópontok kollekcióját kapcsolja össze. Hogy pontosan milyenek azok a
tripletek, amelyeket ez a szintaxis generál, azt részletesen a 7.2.19 Produkció:
parseTypeCollectionPropertyElt szekció írja le. A kollekció felépítése
abban a sorrendben történik, ahogy a csomópont-elemek megjelennek az XML
dokumentumban. Az a kérdés, azonban, hogy ez a sorrend szignifikáns-e a
feldolgozás szempontjából, kizárólag az alkalmazásoktól függ, ezt tehát itt
nem tárgyaljuk.
A 19. ábra leír egy kosarat (basket), amelyben
háromféle gyümölcs van: banán, alma és körte (banana, apple, pear). A kosár
tartalmát három csomópont-elem kollekciójával ábrázolja a "gyümölcs tartalma"
(ex:hasFruit) tulajdonságelemen belül, a fentebb ismertetett
módszerrel.
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/">
<rdf:Description rdf:about="http://example.org/basket">
<ex:hasFruit rdf:parseType="Collection">
<rdf:Description rdf:about="http://example.org/banana"/>
<rdf:Description rdf:about="http://example.org/apple"/>
<rdf:Description rdf:about="http://example.org/pear"/>
</ex:hasFruit>
</rdf:Description>
</rdf:RDF>
Az rdf:ID attribútumot használhatjuk egy tulajdonságelemben
annak a tripletnek a tárgyiasítására/megtestesítésére (reification), amelyet
generál (a részleteket lásd a 7.3
Tárgyiasítási szabályok szekcióban). A triplet tényleges azonosítója egy
abszolút RDF URI
hivatkozás, amelyet egy – szkópban lévő bázis-URI-hez viszonyított
– olyan relatív URI hivatkozásból állítunk elő, mely egy '#'
karakterből és az rdf:ID értékéből áll. Így pl. egy
rdf:ID="triple" azonosítás egyenértékű egy olyan RDF URI
hivatkozással, amelyet a bázis-URI-hez viszonyított #triple
név reprezentál. Minden olyan azonosítópárnak, mely egy rdf:ID
attribútum értékéből és egy bázis-URI-ből áll, egyedinek kell lennie egy
RDF/XML dokumentumon belül (lásd: constraint-id).
A 20. példában egy rdf:ID attribútum
szerepel, amelyet egy olyan triplet tárgyiasítására használunk, amelyet az
ex:prop tulajdonságelemből állítunk elő úgy, hogy a
tárgyiasított tripletre történő RDF URI
hivatkozás végeredményben a
http://example.org/triples/#triple1 lesz. [A példa által generált triplet és a
"tárgyiasító négyes" tripletjei megtekinthetők az example20.nt weboldalon – a ford.]
<?xml version="1.0"?>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:ex="http://example.org/stuff/1.0/"
xml:base="http://example.org/triples/">
<rdf:Description rdf:about="http://example.org/">
<ex:prop rdf:ID="triple1">blah</ex:prop>
</rdf:Description>
</rdf:RDF>
A "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD
NOT", "RECOMMENDED", "MAY" és "OPTIONAL" kulcsszavakat ebben a dokumentumban
úgy kell értelmezni, ahogyan azt az RFC 2119 [KEYWORDS] szabvány definiálja. [Az ilyen kifejezéseket tartalmazó
dokumentumrészek magyar fordításában (zárójelben) megadjuk ezeket a
szabványosított jelentésű angol szavakat, hogy formálisan is fennmaradjon a
kompatibilitás ezzel az RFC-vel – a ford.]
Minden karakterlánc, amelyhez nem adunk külön minősítést, mindig [UNICODE] karakterláncot jelent; azaz olyan
karakterek sorozatát, amelyeket egy Unicode kódponttal ábrázolunk. (Lásd a [CHARMOD] dokumentum 3.4
Strings szekciójánál.)
Az Internet media típus / MIME típus az RDF/XML esetén az
"application/rdf+xml" – lásd a RFC 3023 [RFC-3023] szabvány 8.18. szekciójában.
Ajánlott, hogy az RDF/XML fájlok a ".rdf" (csupa kisbetűs)
kiterjesztést kapják minden platformon.
Ajánlott, hogy azok az RDF/XML fájlok, amelyeket a Macintosh HFS
fájlrendszerben tárolnak, az "rdf " fájltípus nevet kapják
(csupa kisbetűvel, és szóköz karakterrel a negyedik karakterpozícióban).
Megjegyzés (Informatív): Az aboutEach és
aboutEachPrefix neveket az RDF-mag Munkacsoport eltávolította a
nyelvből és az RDF szókészletből. Lásd ezeknek a problémáknak a lezárását az
RDF témakövető dokumentáció rdfms-abouteach
és rdfms-abouteachprefix
pontjában.
Megjegyzés (Informatív): A List,
first, rest és nil neveket felvették a
szókészletbe az rdfms-seq-representation
kérdés megoldása kapcsán. Az XMLLiteral és datatype
kifejezések is a szókészletbe kerültek az RDF adattípusainak támogatására.
Ugyancsak a szókészlet részévé vált a nodeID név az rdfms-syntax-incomplete
kérdés megoldása érdekében. (Lásd az RDF-maggal kapcsolatos nyitott kérdések
listáját (RDF Core Issues
List).
Az RDF névtér
URI hivatkozás (vagy névtér-név):
http://www.w3.org/1999/02/22-rdf-syntax-ns# , amelyet XML-ben
tipikusan az rdf prefixszel helyettesítünk, bár erre a célra
bármilyen más prefixet is használhatnánk. Az RDF szókészletet ezzel a
névtér-névvel azonosítjuk. A szókészlet csupán az alábbi kifejezésekből
áll:
- Szintaktikai nevek – nem fogalmak
RDF Description ID about parseType resource li nodeID
datatype
- Osztálynevek
Seq Bag Alt Statement Property XMLLiteral List
- Tulajdonságnevek
subject predicate object type value first rest _n
,
ahol n egy nullánál nagyobb decimális egész szám, vezető
nullák nélkül írva.
- Erőforrás-nevek
nil
További nevek nincsenek definiálva, tehát ha ilyenek előfordulnának, egy
figyelmeztetést kellene (SHOULD) kiadnia a szoftvernek, de egyébként
normálisan kellene folytatnia a feldolgozást.
Az RDF/XML dokumentumokon belül nem megengedett olyan XML névterek
használata, amelyeknek a névtér-neve egy olyan `RDF névtér URI hivatkozás`, amelyhez további karakterek is fűződnek. [Az ebben a mondatban szereplő, speciálisan
idézőjelezett `RDF névtér URI hivatkozás` egy hiperlink a kifejezés magyarázatát adó
szövegrészre. A továbbiakban is találkozunk ilyen hiperlinkekkel – a
ford.]
Ezen a dokumentumon végig, az rdf:név formájú
kifejezést használjuk annak jelölésére, hogy a név az RDF
szókészletből való, és annak URI hivatkozása
az `RDF
névtér URI hivatkozás` és a név
egybetoldásából keletkezik. Például az rdf:type teljes URI hivatkozása
http://www.w3.org/1999/02/22-rdf-syntax-ns#type
Az RDF Gráf
(lásd Az RDF alapfogalmai és
absztrakt szintaxisa 3. fejezetében) háromféle csomópontot és egyféle
állítmányt definiál:
- RDF URI
hivatkozás csomópontok és állítmányok
Egy RDF
URI hivatkozás (lásd Az
RDF alapfogalmai és absztrakt szintaxisa 3.1 szekciójában) a
következő formákban adható meg:
- egy XML attribútum értékeként, amely egy olyan relatív URI
hivatkozás, amelyet a szkópban lévő bázis-URI-hez képest
értelmezünk (ahogyan azt az 5.3
szekció leírja), hogy így egy abszolút RDF URI
hivatkozást kapjunk;
- egy XML névtér-névvel minősített elemnévként vagy
attribútum-névként (QName);
- egy
rdf:ID attribútum értékeként.
Az RDF/XML-en belül a minősített neveket (QNames) oly módon
transzformáljuk RDF URI
hivatkozásokká, hogy az XML lokális nevet a névtér-névhez (URI
hivatkozáshoz) illesztjük. Például, ha a foo XML
névtér-prefixhez tartozó névtér-név (URI hivatkozás)
http://example.org/somewhere, akkor a foo:bar
minősített név a http://example.org/somewhere/bar RDF URI
hivatkozásnak felelne meg. Megjegyzendő, hogy ez korlátozza, hogy
milyen RDF
URI hivatkozások állíthatók elő, valamint hogy ugyanaz az URI
többféleképpen is előállítható.
Az rdf:ID értéket úgy
transzformáljuk RDF URI
hivatkozásokká, hogy az attribútum értékét egy "#" karakterrel
elválasztva a szkópban lévő bázis-URI-hez illesztjük, ahogyan azt az 5.3 URI-k létrehozása szekció leírja.
- Literál-csomópontok (mindig tárgy-csomópontok)
Az RDF
literálok (lásd Az RDF
alapfogalmai és absztrakt szintaxisa 6.5 szekciójában) lehetnek típus nélküli
literálok (lásd uo.) vagy tipizált
literálok (lásd uo.). Az utóbbiakba beleértendők az XML
literálok (lásd uo. az 5. XML tartalom az RDF gráfon belül
című fejezetben.)
- Ürescsomópont-azonosítók
Az üres
csomópontoknak megkülönböztetett identitásuk van az RDF gráfban.
Amikor a gráfot egy szintaxissal írjuk le (pl. RDF/XML-ben), akkor
ezeknek az üres csomópontoknak szükségük van gráfon belüli
azonosítókra, és egy olyan szintaxisra, mely megőrzi ezt a
megkülönböztetést. Ezeket a helyi azonosítókat ürescsomópont-azonosítóknak
nevezzük, és az RDF/XML-ben az rdf:nodeID attribútum
értékeként használjuk egy olyan szintaxissal, amelyet a Produkció: nodeIdAttr definiál. Az
ürescsomópont-azonosítókat az RDF/XML az XML Információhalmaz dokumentum-információtételének
szkópjába utalja.
Ha ürescsomópont-azonosítót nem adunk meg explicit módon egy
rdf:nodeID attribútum értékeként, akkor azt elő kell
állítani (a 6.3.3 szekció
táblázatában lévő generated-blank-node-id() sor
definíciója szerint.) Az ilyen "generált ürescsomópont-azonosítók" nem
ütközhetnek az rdf:nodeID attribútumok értékeiből
származtatott egyetlen ilyen azonosítóval sem. Ez implementálható
bármilyen módszerrel, amely fenntartja az összes üres csomópont egyedi
identitását a gráfon belül, vagyis, ha sohasem adja ugyanazt az
ürescsomópont-azonosítót két vagy több különböző üres csomópontnak. Az
egyik lehetséges módszer az, hogy egy konstans prefixet adunk minden
rdf:nodeID attribútum értékéhez, és biztosítjuk, hogy a
generált ürescsomópont-azonosítók egyike sem használja ezt a prefixet.
A másik módszer az lehetne, ha minden rdf:nodeID
attribútum értékét leképeznénk egy-egy új, generált
ürescsomópont-azonosítóvá, és ezt a leképezést végrehajtanánk minden
ilyen értékre az adott RDF/XML dokumentumban.
Az RDF/XML támogatja az XML Base [XML-BASE] előírást, mely egy `base-uri` akcesszort definiál minden egyes `root eseményhez` és `elem eseményhez`. A
relatív URI hivatkozásokat RDF URI
hivatkozásokká kell konvertálni az XML Base [XML-BASE] (és RFC 2396) által specifikált
algoritmus szerint. Ezek a specifikációk azonban nem specifikálnak
algoritmust külön az erőforrásrész-azonosítók (mint pl. a #foo
vagy az üres karakterlánc "") RDF URI
hivatkozássá konvertálására. Az RDF/XML-ben egy erőforrásrész-azonosítót
úgy konvertálunk RDF URI
hivatkozássá, hogy az erőforrásrész-azonosítót a szkópban lévő bázis-URI
végéhez illesztjük. Az üres karakterláncot úgy konvertáljuk RDF URI
hivatkozássá, hogy behelyettesítjük azt a szkópban lévő bázis-URI-vel.
Ezeknek az eseteknek a teszteléséhez az alábbi teszt-fájlok állnak
rendelkezésre:
Egy üres saját dokumentumra hivatkozást ("") a bázis-URI URI részével
helyettesítjük; az erőforrásrész-azonosító részt figyelmen kívül hagyjuk).
Lásd az Uniform Resource
Identifiers (URI) [URIS] 4.2 szekciójában.
Implementációs megjegyzés (Informatív): Amikor egy
hierarchikus bázis-URI-t használunk, amelynek nincs útvonal komponense (/),
akkor azt hozzá kell adni, mielőtt a bázis-URI-t felhasználnánk a
konverzióhoz.
- constraint-id
- Az idAttr produkció minden alkalmazása
megegyezik egy attribútummal. Az ilyen attribútum `string-value`
akcesszorából és `base-uri`
akcesszorából alkotott pár egyedi `egy` adott RDF/XML dokumentumon
belül.
A nevek szintaxisának meg kell egyeznie az rdf-id
produkcióval.
- Definíció:
- Egy RDF dokumentum egy RDF Gráf
konkrét szintaxissá történő szerializációja (sorosítása).
- Definíció:
- Egy RDF/XML
dokumentum egy olyan RDF dokumentum, amelyet az RDF számára
ajánlott XML adatátviteli szintaxis szerint írtak meg, ahogyan azt a
jelen dokumentum definiálja.
- Megfelelés:
- Egy RDF/XML
dokumentum megfelelő RDF/XML
dokumentumnak tekinthető, ha a jelen specifikáció szerint
készült.
Ez a dokumentum az RDF/XML szintaxisát egy szimbólum-ábécére alkalmazott
nyelvtanként specifikálja. A szimbólumokat eseményeknek (event)
nevezzük az [XPATH] – Information Set Mapping
stílusában. Az események sorozatát rendesen egy XML dokumentumból
származtatjuk, és ilyenkor ezek dokumentum sorrendben szerepelnek, ahogyan
alább, a 6.2
Információhalmaz-leképezés szekció definiálja. Annak a sorozatnak,
amelyet ezek az események alkotnak, hasonlónak kell lennie ahhoz az
esemény-sorozathoz, amelyet a [SAX2] XML API
produkálna ugyanabból az XML dokumentumból. Az események sorozatát
ütköztethetjük a nyelvtannal, hogy megállapíthassuk, hogy megfelelnek-e egy
szintaktikailag jól formált RDF/XML-nek.
A nyelvtan produkciói akciókat is tartalmazhatnak, amelyek akkor futnak
le, amikor az adott produkciót felismeri a szoftver. Ezeknek az akcióknak az
összessége meghatározza azt a transzformációt, mely bármilyen,
szintaktikailag jól formált RDF/XML eseménysorozatból egy triplet nyelven (N-Triples) kódolt gráfot
állít elő.
Az itt megadott modell egy lehetséges módját mutatja meg annak, hogy
miként állíthatjuk elő egy RDF/XML dokumentum RDF gráf ábrázolását.
Ez nem erőltet semmilyen implementációs módszert; bármilyen módszer, amely
ugyanabból az RDF/XML-ből ugyanazt az RDF gráfot állítja
elő, nyugodtan használható.
Részletesebben:
- Ez a specifikáció megengedi egy RDF gráf bármifajta ábrázolását
(lásd [RDF-FOGALMAK]); és különösen, nem
várja el az N-Triples triplet
nyelv alkalmazását.
- Ez a specifikáció nem várja el az [XPATH] vagy
a [SAX2] alkalmazását.
- Ez a specifikáció semmilyen megkötést nem tesz arra a sorrendre sem,
amelyben az RDF/XML-t transzformáló szoftver felépíti a kimeneti
gráfot.
- Az a szoftver, mely az RDF/XML-t gráf ábrázolásúra fordítja le,
eltávolíthatja (MAY eliminate) a duplikált állítmány-éleket.
A szintaxis nem támogatja a rosszul formált XML dokumentumokat, sem pedig
azokat a dokumentumokat, amelyek más okból nem tartalmaznak XML
Információhalmazt; (például, amelyek nem felelnek meg a Namespaces in
XML [XML-NS] előírásoknak).
Az XML Információhalmaz (XML Infoset) elvárja az XML Base [XML-BASE] konstrukció támogatását. Az RDF/XML
használja a [base URI] információtétel tulajdonságot (information item
property), ahogyan azt az 5.3 szekció
definiálja.
A specifikáció egy olyan XML Információhalmazt [INFOSET] vár el, mely támogatja legalább az
alábbi RDF/XML információtételeket és tulajdonságokat:
- Dokumentum
információtétel
- [dokumentum elem], [children], [base URI]
- Elem
információtétel
- [local name], [namespace name], [children], [attributes], [parent],
[base URI]
- Attribute
információtétel
- [local name], [namespace name], [normalized value]
- Charakter
információtétel
- [character code]
Az alábbi elemek nincsenek leképezve adatmodell-eseményekre:
- Feldolgozó
utasítás információtétel
- Ki nem
terjesztett entitás-hivatkozás információtétel
- Kommentár
információtétel
- Dokumentumtípus-deklaráció
információtétel
- Elemezetlen
entitás információtétel
- Megjegyzés
információtétel
- Névtér
információtétel
Az itt fel nem sorolt információtételek és tulajdonságok szintén nincsenek
leképezve adatmodell-eseményekre.
Azok az elem információtételek, amelyek fenntartott XML nevekkel
rendelkeznek, (lásd Name az XML 1.0 dokumentumban),
ugyancsak nincsenek megfeleltetve adatmodell-eseményeknek. Ide tartozik az
összes olyan elem, amelynek a [prefix] tulajdonsága az xml
karakterekkel kezdődik (kisbetű/nagybetű-független összehasonlításban) és
mindazok, amelyeknek a [prefix] tulajdonsága nem rendelkezik értékkel,
továbbá, amelyeknek xml karakterekkel kezdődő helyi nevük [local
name] van (ugyancsak kisbetű/nagybetű-független összehasonlításban).
Minden olyan információtétel az RDF/XML dokumentumon belül, mely egyezik a
parseTypeLiteralPropertyElt
produkcióval, egy XML-literált
takar, és nem követi ezt a leképezést. További információkért lásd a parseTypeLiteralPropertyElt
produkciót.
Ennek a szekciónak a feladata kielégíteni a megfelelési (Conformance)
követelményeket az [INFOSET] specifikáció
szerint. Ennek érdekében specifikálja azokat az információtételeket és
tulajdonságokat amelyek ennek a specifikációnak az implementációjához
szükségesek.
A következő alszekciókban az események kilenc típusát definiáljuk. A
legtöbb esemény az XML Infoset egy-egy információtételből épül fel (kivétel
az URI hivatkozás, üres csomópont, típus nélküli literál és a tipizált literál). Egy
esemény-konstruktor hatása az, hogy egy új eseményt állít elő, önálló
identitással, mely különbözik minden más eseménytől. Az események akcesszor
műveletekkel rendelkeznek, és a legtöbbnek string-value
(karakterlánc érték) akcesszora van, mely lehet egy statikus érték, és lehet
egy dinamikusan előállított érték is.
A dokumentum
információtétel-ből állítjuk elő és a következő akcesszorokat és
értékeket kapja:
- dokumentum-elem
- Beállítva a dokumentum információtétel [dokumentum-elem]
tulajdonságának értékére.
- children (gyermekek)
- Beállítva a dokumentum információtétel [children]
tulajdonságának értékére.
- base-uri (báris-URI)
- Beállítva a dokumentum információtétel [base URI]
tulajdonságának értékére.
- language (nyelv)
- Beállítva az üres karakterláncra.
Egy elem
információtétel-ből állítjuk elő, és következő akcesszorokat és értékeket
kapja:
- local-name (helyi név)
- Beállítva az elem információtétel [local name]
tulajdonságának értékére.
- namespace-name
(névtér-név)
- Beállítva az elem információtétel [namespace name]
tulajdonságának értékére.
- children (gyermekek)
- Beállítva az elem információtétel [children] tulajdonságának
értékére.
- base-uri (bázis-URI)
- Beállítva az elem információtétel [base URI] tulajdonságának
értékére.
- attributes (attribútumok)
Az elem információtétel [attributes] tulajdonságának
értékéből állítjuk elő, ami nem más, mint attribute
információtételek halmaza.
Ha ez a halmaz tartalmaz egy xml:lang
attribute információtételt ([namespace name] tulajdonság =
"http://www.w3.org/XML/1998/namespace" értékkel és egy [local name]
tulajdonság = "lang" értékkel), akkor azt eltávolítjuk az
attribute információtételek halmazából és a `language`
akcesszort beállítjuk az attribute információtétel
[normalized-value] tulajdonságára.
Minden megmaradó rezervált XML név (lásd Name az
XML 1.0-ban)
most már el van távolítva a halmazból, vagyis: minden olyan
attribute információtétel a halmazban, amelynek a [prefix]
tulajdonsága xml karakterlánccal kezdődik
(kisbetű/nagybetű-független összehasonlításban), továbbá minden olyan
attribute információtétel, amelynek a [prefix] tulajdonsága
nem rendelkezik értékkel, vagy amelyiknek a [local name] tulajdonsága
xml karakterlánccal kezdődik (kisbetű/nagybetű-független
összehasonlításban). Megjegyzendő, hogy a [base URI] akcesszor értékét
kiszámítja az XML Base, mielőtt bármelyik xml:base
attribute információtételt törölné.
Az attribute információtételek megmaradó halmaza most már
az attribute események új
halmazának felépítésére használható, amit azután, értékként, ehhez az
akcesszorhoz rendelünk.
- URI
- Beállítva egy olyan karakterlánc értékre, mely a
namespace-name akcesszor és a
local-name akcesszor értékének összeillesztésével jön
létre.
- URI-string-value (az
URI karakterlánc-értéke)
Értéke a következő elemek egymás után fűzéséből áll, ebben a
sorrendben: "<", az `URI` akcesszor escape-rezolvált értéke, ">".
Az `URI` akcesszor
escape-rezolúciója a tripletnyelv (N-Triples) URI
hivatkozásaira megadott escape-rezolúciót használja, ahogyan azt az
N-Triples dokumentum 3.3 URI
References szekciója definiálja.
- li-counter
(listaelem-számláló)
- Beállítva az 1 értékre.
- language (nyelv)
- Beállítva a fentebb leírt `attributes`
akcesszornál. Ha az attribútumokból nem kapott értéket, akkor az
értékét a szülő esemény (akár a Gyökér
Esemény akár Elem Esemény)
language akcesszora szerint lesz beállítva, ami lehet egy üres
karakterlánc is.
- subject (alany)
- Nincs kezdeti értéke. Az értéke egy Identifier esemény lesz. Ezt az
akcesszort olyan elemekben használjuk, amelyek egy csomóponttal
foglalkoznak az RDF gráfban, és ez általában egy kijelentés alanya.
Nem rendelkezik akcesszorokkal. A befogadó elem végét jelöli meg a
sorozatban.
Az attribute
információtétel-ből állítjuk elő, és az alábbi akcesszorokat és értékeket
kapja:
- local-name (helyi név)
- Beállítva az attribute információtétel [local name]
tulajdonságának értékére.
- namespace-name
(névtér-név)
- Beállítva az attribute információtétel [namespace name]
tulajdonságának értékére.
- string-value
(karakterlánc-érték)
- Beállítva az attribute információtétel [normalized value]
tulajdonságának értékére, ahogyan az [XML]
specifikálja (ha egy olyan attribútum, amelynek a normalizált értéke
egy zéró hosszúságú karakterlánc, akkor a string-value
értéke szintén egy zéró hosszúságú karakterlánc lesz).
- URI
Ha a `namespace-name`
akcesszor jelen van, akkor a `namespace-name`
akcesszor és a `local-name`
akcesszor egybetoldott értékére van állítva. Egyébként, ha a `local-name` egy
ID, about, resource,
parseType vagy egy type, akkor az `RDF
névtér URI hivatkozás` és a `local-name`
akcesszor egybetoldott értékére van állítva. Másfajta, névtér nélküli
`local-name`
akcesszor érték használata tilos.
A névtér-minősítés nélküli nevek egy korlátozott halmazának a
támogatása kötelező (REQUIRED), és arra szolgál, hogy lehetővé tegye,
hogy az [RDF-MS]-ben specifikált RDF/XML
dokumentumok érvényesek maradjanak. Új dokumentumok lehetőleg ne
használják (SHOULD NOT use) ezeket a minősítés nélküli attribútumokat,
és az alkalmazások dönthetnek úgy (MAY choose), hogy egy
figyelmeztetést adnak ki, amikor egy ilyen minősítés nélküli forma
felbukkan az elemzett dokumentumban.
Az RDF
URI hivatkozások előállítása XML attribútumokból, létrehozhatja
ugyanazokat az RDF URI
hivatkozásokat különböző XML attribútumokból. Ez félreértésekre
vezethet a nyelvtanban az attribute események ütköztetésénél
(ilyen eset, pl., amikor egy rdf:about és egy XML
about attribútum is jelen van). Azok a dokumentumok,
amelyekben ez előfordul, illegálisak.
- URI-string-value (az
URI karakterlánc értéke)
- A következő elemek egymás után fűzéséből áll, ebben a sorrendben:
"<", az `URI` akcesszor
escape-rezolvált értéke, és ">".
Az `URI` akcesszor
escape-rezolúciója a tripletnyelv (N-Triples) URI
hivatkozásaira megadott escape-rezolúciót használja, ahogyan azt az
N-Triples dokumentum 3.3 URI
References szekciója definiálja.
Egy vagy több, egymás után következő character
információtétel sorozatából állítjuk elő. Az egyetlen akcesszora:
- string-value
(karakterlánc-érték)
- Beállítva annak a karakterláncnak az értékére, amelyet az összes
character információtétel [character
code] tulajdonságának értékéből fűzünk egybe.
Egy esemény az RDF URI
hivatkozások számára, mely a következő akcesszorokkal rendelkezik:
- identifier (azonosító)
- Egy karakterlánc-értéket kap, amelyet egy RDF URI
hivatkozás-ként használunk
- string-value
(karakterlánc-érték)
- Értéke a következő elemek egymás után fűzéséből áll, ebben a
sorrendben: "<", az `identifier`
akcesszor escape-rezolvált értéke, és ">".
Az `identifier`
akcesszor escape-rezolúciója a tripletnyelv (N-Triples) URI
hivatkozásaira megadott escape-rezolúciót használja, ahogyan azt az
N-Triples dokumentum 3.3 URI
References szekciója definiálja.
Ezeket az eseményeket úgy állítjuk elő, hogy egy értéket adunk az `identifier`
akcesszornak.
További információk az RDF gráfban előforduló azonosítókról, az 5.2 szekcióban találhatók.
Egy esemény az ürescsomópont-azonosítók
számára, mely a következő akcesszorokat tartalmazza:
- identifier
(azonosító)
- Egy karakterlánc-értéket kap.
- string-value
(karakterlánc-érték)
- Ennek értéke az `identifier`
akcesszor értékének a függvénye. Az érték egy "_:" karakterlánccal
kezdődik, és az egész értéknek meg kell egyeznie (MUST) az N-Triples nodeID
produkciójával. A függvénynek fenn kell tartania (MUST) az üres
csomópontok egyedi azonosítását, ahogyan azt az 5.2 Azonosítók szekció tárgyalja.
Ezeket az eseményeket úgy állítjuk elő, hogy egy értéket adunk az `identifier`
akcesszornak.
További információk az RDF gráfban előforduló azonosítókról az 5.2 szekcióban találhatók.
Egy esemény a típus nélküli
literálok számára, mely az alábbi akcesszorokkal rendelkezhet:
- literal-value (literál
érték)
- Egy karakterlánc-értéket kap.
- literal-language (a
literál nyelve)
- Egy karakterlánc-értéket kap, amelyet nyelv-tegként
használunk egy RDF típus nélküli literálban.
- string-value (karakterlánc
érték)
Az értékét a többi akcesszor értékéből számítjuk ki, a
következőképpen:
Ha a `literal-language`
egy üres karakterlánc, akkor az érték a következő elemek összefűzéséből
jön létre: egy """ (1 idézőjel), a `literal-value`
akcesszor escape-rezolvált értéke, és egy """ (1 idézőjel).
Egyébként az érték a következő elemek összefűzéséből jön létre: egy
""" (1 idézőjel), a `literal-value`
akcesszor escape-rezolvált értéke, ""@" (1 idézőjel és egy 'kukac'
karakter), és a `literal-language`
akcesszor értéke.
A `literal-value`
akcesszor escape-rezolúciója a tripletnyelv (N-Triples)
karakterláncaira megadott escape-rezolúciót használja, ahogyan azt az
N-Triples
dokumentum 3.2
Strings szekciója definiálja (például ilyen karakterek átugratására
mint az idézőjel (") )
Ezeket az eseményeket úgy állítjuk elő, hogy egy értéket adunk a `literal-value` és a `literal-language`
akcesszoroknak.
Együttműködési megjegyzés (Informatív): Azok a
literálok, amelyek egy kombinált Unicode karakterrel kezdődnek,
engedélyezettek, azonban ez együttműködési problémákhoz vezethet a szoftverek
között (lásd a további információkat a [CHARMOD]-nál)
Egy esemény a tipizált
literálok számára, mely a következő akcesszorokat kaphatja:
- literal-value
(literál érték)
- Egy karakterlánc-értéket kap.
- literal-datatype
(literál adattípus)
- Egy olyan karakterlánc értékét veszi fel, amely egy RDF URI
hivatkozás.
- string-value
(karakterlánc érték)
- az érték a következő elemek összefűzéséből jön létre, ebben a
sorrendben: egy """ (1 idézőjel), a `literal-value`
akcesszor escape-rezolvált értéke, egy """ (1 idézőjel), a "^^<"
karakterlánc, a `literal-datatype`
akcesszor escape-rezolvált értéke, és a ">" karakterlánc.
A `literal-value`
akcesszor escape-rezolúciója a tripletnyelv (N-Triples)
karakterláncaira megadott escape-rezolúciót használja, ahogyan azt az
N-Triples
dokumentum 3.2
Strings szekciója definiálja (például ilyen karakterek átugratására
mint az idézőjel (") )
A `literal-datatype`
akcesszor escape-rezolúciója a tripletnyelv (N-Triples)
karakterláncaira megadott escape-rezolúciót használja, ahogyan azt az
N-Triples
dokumentum 3.3 URI
References szekciója definiálja.
Ezeket az eseményeket úgy állítjuk elő, hogy egy értéket adunk a `literal-value` és a `literal-datatype`
akcesszoroknak.
Implementációs megjegyzés (Informatív): Az XML Schema (part
1) [XML-SCHEMA1], szerint white
space normalizáció történik az érvényességellenőrzés (validáció) során a
whiteSpace facet értéke szerint. Az ebben a dokumentumban
végrehajtott szintaxisleképezés csak ez után történik, úgy hogy a
whiteSpace facet-nek formálisan nincs további hatása.
Ahhoz, hogy egy dokumentum teljes XML információhalmazát, dokumentum
sorrendben megadott események sorozatává alakítsuk át, minden
információtételt úgy kell transzformálnunk, ahogyan fentebb leírtuk, s ennek
eredményeként megkapjuk a fa-struktúrába szervezett eseményeket, azok
akcesszoraival és értékeivel együtt. Ezt követően az összes elem
eseményt az alább leírt módon rendezzük át, hogy az események fa-struktúráját
az események dokumentum sorrendben megadott lineáris sorozatává alakítsuk
át.
- Az eredeti elem
esemény
- A children
akcesszor értéke rekurzívan transzformálva, mely az események (esetleg
üres) rendezett listája.
- Egy vége elem
esemény
Az alábbi notációt használjuk egyrészt annak leírására, hogy miként
ütköztetjük a nyelvtani produkciókat az adatmodell 6 fejezetben leírt eseményeinek sorozatával,
másrészt pedig azoknak az akcióknak a leírására, amelyeket találat esetén
végre kell hajtani. Az RDF/XML nyelvtan oly módon van definiálva, hogy a
találatot mutató adatmodell-eseményeket tripletekre képezze le az alábbi
formájú notáció segítségével:
sorszám esemény-típus esemény-tartalom
ahol az esemény-tartalom egy kifejezés, mely az
esemény-típus-nak felel meg (ahogyan a 6.1
szekció leírja), és amelyet egy olyan leíró nyelven adunk meg, amelyet a
következő szekciók ismertetnek. A sorszámot csak hivatkozási célokra
használjuk. A nyelvtani akció magában foglalhatja új tripletek
generálását is a gráf számára, N-Triples nyelven
megfogalmazva.
Az alábbi három szekció leírja az általános, az esemény ütköztető és az
akciós nyelvtani elemek notációit.
Általános nyelvtani notációk.
| Notáció |
Jelentése |
| esemény.accessor |
Az esemény akcesszor értéke. |
rdf:X |
Egy URI, ahogy az 5.1 szekció
definiálja. |
| "ABC" |
Egy karakterlánc A, B, C sorrendű karakterekkel. |
Az esemény ütköztetések nyelvtani notációja.
| Notáció |
Jelentése |
| A == B |
Az A esemény akcesszor megegyezik
B kifejezéssel. |
| A != B |
A nem egyenlő B-vel. |
| A | B | ... |
Az A, B, ... kifejezések alternatívák. |
| A - B |
A kifejezései, B kifejezések
kihagyásával. |
| anyURI. |
Bármilyen URI. |
| anyString. |
Bármilyen karakterlánc. |
| list(item1, item2, ...); list() |
Események rendezett sora. Egy üres lista. |
| set(item1, item2, ...); set() |
Események rendezetlen halmaza. Egy üres halmaz. |
| * |
Zéró vagy több a megelőző kifejezésekből. |
| ? |
Zéró vagy egy a megelőző kifejezésekből. |
| + |
Egy vagy több a megelőző kifejezésekből. |
root(acc1 == value1,
acc2 == value2, ...) |
Ütköztet egy Gyökér
eseményt az akcesszoraival együtt. |
start-elem(acc1 == value1,
acc2 == value2, ...)
children
end-elem() |
Ütközteti Elem
események egy sorozatát akcesszoraikkal együtt; elemtartalomként
esetleg események egy üres listája; egy Vége elem esemény. |
attribute(acc1 == value1,
acc2 == value2, ...) |
Ütköztet egy Attribútum
eseményt az akcesszoraival együtt. |
| text() |
Ütköztet egy Szöveg
eseményt. |
Az akciók nyelvtani notációja.
| Notáció |
Jelentése |
| A := B |
A-hoz rendeli B értékét. |
| concat(A, B, ..) |
Egy karakterlánc előállítása a felsorolt kifejezések megadott
sorrendben történő összeillesztésével. |
| resolve(e, s) |
Egy karakterlánc előállítása, ahol az s karakterlánc egy
relatív URI hivatkozás e `base-uri`
akcesszorára, ahogy az 5.3 URI-k
létrehozása szekció leírja. Az így létrejövő karakterlánc egy
teljes RDF
URI hivatkozást reprezentál. |
| generated-blank-node-id() |
Egy karakterlánc előállítása egy új, egyedi, generált ürescsomópont-azonosító
céljára, ahogy az 5.2 Azonosítók
szekció definiálja. |
| esemény.accessor := value |
Egy esemény-akcesszort a value értékre állítja. |
| uri(identifier := value) |
Egy URI hivatkozás
esemény előállítása. |
| bnodeid(identifier := value) |
Egy új Ürescsomópont-azonosító
esemény előállítása. Lásd az 5.2
Azonosítók szekcióban is. |
literal(literal-value := string,
literal-language := language, ...) |
Egy új Típus nélküli
literál esemény előállítása. |
| typed-literal(literal-value := string, ...) |
Egy új Tipizált
literál esemény előállítása. |
| 7.2.2 coreSyntaxTerms |
rdf:RDF | rdf:ID | rdf:about
| rdf:parseType | rdf:resource |
rdf:nodeID | rdf:datatype |
| 7.2.3 syntaxTerms |
coreSyntaxTerms |
rdf:Description | rdf:li |
| 7.2.4 oldTerms |
rdf:aboutEach | rdf:aboutEachPrefix |
rdf:bagID |
| 7.2.5 nodeElementURIs |
anyURI - ( coreSyntaxTerms | rdf:li |
oldTerms ) |
| 7.2.6 propertyElementURIs |
anyURI - ( coreSyntaxTerms |
rdf:Description | oldTerms ) |
| 7.2.7 propertyAttributeURIs |
anyURI - ( coreSyntaxTerms |
rdf:Description | rdf:li | oldTerms ) |
| 7.2.8 doc |
root(dokumentum-elem
== RDF, children == list(RDF)) |
| 7.2.9 RDF |
start-elem(URI ==
rdf:RDF, attributes == set())
nodeElementList
end-elem() |
| 7.2.10 nodeElementList |
ws* (nodeElement ws* )* |
| 7.2.11 nodeElement |
start-elem(URI == nodeElementURIs
attributes == set((idAttr | nodeIdAttr | aboutAttr )?, propertyAttr*))
propertyEltList
end-elem() |
| 7.2.12 ws |
Egy Szöveg esemény mely
white space-szel egyenlő, ahogy az [XML]
definiálja a White Space Rule [3] S a Common
Syntactic Constructs szekcióban. |
| 7.2.13 propertyEltList |
ws* (propertyElt ws* ) * |
| 7.2.14 propertyElt |
resourcePropertyElt | literalPropertyElt | parseTypeLiteralPropertyElt |
parseTypeResourcePropertyElt
| parseTypeCollectionPropertyElt
| parseTypeOtherPropertyElt
| emptyPropertyElt |
| 7.2.15 resourcePropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?))
ws* nodeElement ws*
end-elem() |
| 7.2.16 literalPropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?, datatypeAttr?))
text()
end-elem() |
| 7.2.17 parseTypeLiteralPropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?, parseLiteral))
literal
end-elem() |
| 7.2.18 parseTypeResourcePropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?, parseResource))
propertyEltList
end-elem() |
| 7.2.19 parseTypeCollectionPropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?, parseCollection))
nodeElementList
end-elem() |
| 7.2.20 parseTypeOtherPropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?, parseOther))
propertyEltList
end-elem() |
| 7.2.21 emptyPropertyElt |
start-elem(URI == propertyElementURIs ), attributes == set(idAttr?, ( resourceAttr | nodeIdAttr )?, propertyAttr*))
end-elem() |
| 7.2.22 idAttr |
attribute(URI ==
rdf:ID, string-value == rdf-id) |
| 7.2.23 nodeIdAttr |
attribute(URI ==
rdf:nodeID, string-value == rdf-id) |
| 7.2.24 aboutAttr |
attribute(URI ==
rdf:about, string-value == URI-reference) |
| 7.2.25 propertyAttr |
attribute(URI == propertyAttributeURIs, string-value == anyString) |
| 7.2.26 resourceAttr |
attribute(URI ==
rdf:resource, string-value == URI-reference) |
| 7.2.27 datatypeAttr |
attribute(URI ==
rdf:datatype, string-value == URI-reference) |
| 7.2.28 parseLiteral |
attribute(URI ==
rdf:parseType, string-value ==
"Literal") |
| 7.2.29 parseResource |
attribute(URI ==
rdf:parseType, string-value ==
"Resource") |
| 7.2.30 parseCollection |
attribute(URI ==
rdf:parseType, string-value ==
"Collection") |
| 7.2.31 parseOther |
attribute(URI ==
rdf:parseType, string-value == anyString - ("Resource" | "Literal" |
"Collection") ) |
| 7.2.32 URI-reference |
Egy RDF
URI hivatkozás. |
| 7.2.33 literal |
Bármilyen XML elemtartalom, mely megengedett az [XML] Content of Elements Rule [43] content
definíciója szerint a 3.1
Start-Tags, End-Tags, and Empty-Element Tags szekcióban. |
| 7.2.34 rdf-id |
Egy attribútum esemény `string-value`
akcesszor érték, mely egyezik bármilyen legális [XML-NS] NCName
névvel. |
Ha az RDF/XML egy önálló XML dokumentum (melyet egy ilyen prezentáció
azonosít mint egy application/rdf+xml RDF MIME
type objektum, vagy valamilyen más eszköz), akkor a nyelvtan indulhat a
doc produkcióval, vagy egy nodeElement produkcióval.
Ha tartalom a kontextusból felismerhetően RDF/XML (például, amikor az
RDF/XML be van ágyazva más XML tartalomba), akkor a nyelvtan indulhat vagy
egy Elem esemény RDF produkciójával (de csak akkor, ha az elem legális az
XML-nek ezen a pontján), vagy indulhat egy nodeElementList produkcióval (de csak akkor, ha
az elem tartalma legális, mivel elemek listájáról van szó). Az ilyen
beágyazott RDF/XML-nél a `base-uri` értékét a legkülső elemben be kell állítani a
befogadó XML-ből, mivel ilyenkor nem áll rendelkezésre Gyökér esemény. Megjegyzendő, hogy ha
ilyen beágyazás történik, akkor a nyelvtanba többször is be lehet lépni, de
nem várható el, hogy az elemző állapota a két belépés között megmarad.
rdf:RDF | rdf:ID | rdf:about |
rdf:parseType | rdf:resource |
rdf:nodeID | rdf:datatype
Az RDF szókészlet 5.1 szekcióban
felsorolt szintaktikai kifejezéseinek egy részhalmaza, mely az RDF/XML-ben
használható.
Az összes olyan szintaktikai kifejezés az 5.1 szekcióban felsorolt RDF szókészletből,
mely az RDF/XML-ben használható.
rdf:aboutEach | rdf:aboutEachPrefix |
rdf:bagID
Ezek olyan nevek az RDF szókészletből,
amelyeket mára már töröltek a nyelvből. (A további részletek tekintetében
lásd az rdfms-aboutEach-on-object,
az rdfms-abouteachprefix,
és a timbl-01
kérdés megoldását az RDF-mag témakövető dokumentációjának jelzett
helyein).
Azok az RDF URI
hivatkozások, amelyek engedélyezettek csomópont-elemekben.
Azok az URI-k, amelyek engedélyezettek tulajdonságelemekben.
Azok az RDF URI
hivatkozások, amelyek engedélyezettek tulajdonság-attribútumokban.
Egy e csomópont-elem számára néhány attribútum feldolgozását el
kell végezni az egyéb munkák előtt (például mielőtt a gyermek
eseményekkel, vagy más attribútumokkal foglalkoznánk). Ezek bármilyen
sorrendben feldolgozhatók:
Ha e.subject üres, akkor
e.subject := bnodeid(identifier :=
generated-blank-node-id()).
Akkor az alábbiak végrehajthatók bármilyen sorrendben:
- Ha
e.URI !=
rdf:Description akkor a következő tripletet hozzáadjuk a
gráfhoz:
- Ha
létezik egy a attribútum a propertyAttr-ban, ahol a.URI ==
rdf:type akkor
u:=uri(identifier:=resolve(a.string-value)) és a
következő tripletet hozzáadjuk a gráfhoz:
- Minden
olyan a attribútum esetén mely megegyezik egy propertyAttr produktummal (de nem
rdf:type), a Unicode karakterlánc a.string-value értékének
Normal Form C[NFC] kódolásúnak kellene (SHOULD)
lennie, o := literal(literal-value :=
a.string-value,
literal-language :=
e.language) és a
következő tripletet hozzáadjuk a gráfhoz:
- Kezeljük
a propertyEltList children
eseményeket dokumentum sorrendben.
Ha az e elemnek van egy e.URI = rdf:li lista-eleme,
akkor alkalmazzuk a lista kiterjesztő szabályokat az e.parent elemre
(ahogy a 7.4 szekció leírja), hogy egy új
u URI-t kapjunk, és e.URI := u legyen.
Ennek a produkciónak az akcióját végre kell hajtani az alárendelt
találatok (resourcePropertyElt ... emptyPropertyElt) bármelyikének első akciója
előtt.
Az e elem, valamint az egyetlen benne lévő n nodeElement
számára, először n-t fel kell dolgozni a nodeElement produkció segítségével. Azután a
következő tripletet hozzá kell adni a gráfhoz:
Ha az a rdf:ID attribútum meg van adva, a fenti
triplet tárgyiasítható a 7.3 szekcióban
ismertetett tárgyiasítási szabályok szerint, az i := uri(identifier := resolve(e,
concat("#", a.string-value))) akcióval,
valamint az e.subject :=
i akcióval.
Megjegyezzük, hogy az üres literál eset az emptyPropertyElt produkcióban van definiálva.
Az e elem, és a t szöveg esemény számára a
t.string-value Unicode
karakterláncnak Normal Form C[NFC] kódolásban kell
lennie (SHOULD). Ha a d rdf:datatype attribute meg van
adva, akkor o := typed-literal(literal-value :=
t.string-value, literal-datatype :=
d.string-value)
egyébként o := literal(literal-value := t.string-value, literal-language :=
e.language), és a
következő tripletet hozzáadjuk a gráfhoz:
Ha az a rdf:ID attribútum meg van adva, a fenti
tripletet a 7.3 szekcióban ismertetett
tárgyiasítási szabályok szerint, az i := uri(identifier := resolve(e,
concat("#", a.string-value))) akcióval
valamint az e.subject :=
i akcióval tárgyiasítjuk.
Az e elem és az l literál vagyis, az
rdf:parseType="Literal" tartalom számára. Az l-t nem
transzformálja eseményekké a szintaxis-adatmodell leképezése (ahogyan a 6. Syntaxis adatmodell fejezet megjegyzi),
hanem az XML információtételek XML információhalmaza marad).
Az l-t az alábbi algoritmussal transzformáljuk az XML-literál
lexikális formájára (mely egy Unicode karakterlánc) az x RDF
gráfban. Ez nem egy kötelező implementációs módszer – bármilyen
módszer, mely ugyanezt az eredményt szolgáltatja, szabadon használható:
- Használjuk l-t egy XPath[XPATH] node-set
(egy dokumentum
részhalmaz) felépítésére.
- Alkalmazzuk az Exclusive XML
Canonicalization [XML-XC14N])
hitelesítést, kommentárokkal és az üres InclusiveNamespaces
PrefixList listával, erre a csomóponthalmazra (nodeset-re), hogy
előállítsuk az s oktettsorozatot.
- Ezt az s oktettsorozatot egy x Unicode karakterlánc
(Unicode karakterek sorozata) UTF-8 kódolásának tekinthetjük.
- Az x Unicode karakterláncot az l literál lexikális
formájaként használjuk.
- Ennek az x Unicode karakterláncnak NFC Normal Form C[NFC] kódolásúnak kell lennie.
Ezt követően végrehajtjuk az o := typed-literal(literal-value := x,
literal-datatype :=
http://www.w3.org/1999/02/22-rdf-syntax-ns#XMLLiteral ) akciót,
és a következő tripletet a gráfhoz adjuk:
Ha az a rdf:ID attribútum meg van adva, a fenti
tripletet a 7.3 szekcióban ismertetett
tárgyiasítási szabályok szerint, az i := uri(identifier := resolve(e,
concat("#", a.string-value))) akcióval,
valamint az e.subject :=
i akcióval tárgyiasítjuk.
Az e elem számára, esetleg c üres elem tartalommal.
n := bnodeid(identifier :=
generated-blank-node-id()).
És a következő tripletet a gráfhoz adjuk:
Ha az a rdf:ID attribútum meg van adva, a fenti
tripletet a 7.3 szekcióban ismertetett
tárgyiasítási szabályok szerint, az i := uri(identifier := resolve(e,
concat("#", a.string-value))) akcióval,
valamint az e.subject :=
i akcióval tárgyiasítjuk.
Ha a c elemtartalom nem üres, akkor használjuk az n
eseményt új események sorozatának előállítására, ahogy alább következik:
Ezt követően dolgozzuk fel az eredményül kapott sorozatot a nodeElement produkció segítségével
Az e elem esemény számára, esetleg l üres nodeElementList listával. Végezzük el az
s:=list() hozzárendelést.
Minden f elem esemény számára l-ben, n :=
bnodeid(identifier :=
generated-blank-node-id()), és illesszük n-t az s-hez, hogy
végül megkapjuk az események sorozatát.
Ha s nem üres, n az első eseményazonosító
s-ben, és a következő tripletet adjuk a gráfhoz:
egyébként pedig a következő tripletet adjuk a gráfhoz:
Ha az a rdf:ID attribútum meg van adva, a fenti
tripletet a 7.3 szekcióban ismertetett
tárgyiasítási szabályok szerint, az i := uri(identifier := resolve(e,
concat("#", a.string-value))) akcióval
tárgyiasítjuk.
Ha s üres, egyéb akciót nem kell végrehajtani.
Minden n esemény számára s-ben, és minden neki megfelelő
f elem esemény számára l-ben, a következő tripletet adjuk a
gráfhoz:
Minden egymást követő és egymást átlapoló (n, o)
esemény pár számára s-ben, a következő tripletet adjuk a gráfhoz:
Ha s nem üres, n az utolsó eseményazonosító
s-ben, a következő tripletet adjuk a gráfhoz:
n.string-value
<http://www.w3.org/1999/02/22-rdf-syntax-ns#rest>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#nil> .
A "Resource", "Literal" és "Collection" karakterláncok kivételével, minden
rdf:parseType attribútum-értéket úgy kezelünk, mintha az a
"literal" karakterlánc volna. Ez a produkció úgy ütköztet, és olyan akciót
hajt végre, mintha a találat egy parseTypeLiteralPropertyElt produkció
lenne. További tripleteket nem kell generálni a többi
rdf:parseType érték számára.
Ha nincsenek attribútumok, vagy csak az
opcionális i rdf:ID attribútum van
megadva, akkor o := literal(literal-value:="", literal-language :=
e.language), és a
következő tripletet adjuk a gráfhoz:
és ezután, ha i meg van adva, akkor a fenti tripletet a 7.3 szekcióban ismertetett tárgyiasítási
szabályok szerint, az uri(identifier :=
resolve(e, concat("#", a.string-value))) akcióval
tárgyiasítjuk.
Egyébként pedig
Az alábbiakat bármilyen sorrendben végre lehet hajtani:
Minden a propertyAttr
attribútum számára (tetszőleges sorrendben)
Adjuk a következő tripletet adjuk a gráfhoz:
és ezután, ha az rdf:ID attribute i meg van
adva, akkor a fenti tripletet a 7.3
szekcióban ismertetett tárgyiasítási szabályok szerint, az uri(identifier :=
resolve(e, concat("#", a.string-value))) akcióval
tárgyiasítjuk.
A constraint-id korlátozás érvényes az
rdf:ID attribútum minden értékére.
Az adott r URI hivatkozás esemény, és az s,
p and o kifejezésekből álló kijelentés számára, mely
megfelel egy
N-Triples szintaxisú tripletnek, adjuk a következő tripleteket a
gráfhoz:
r.string-value
<http://www.w3.org/1999/02/22-rdf-syntax-ns#subject> s
.
r.string-value
<http://www.w3.org/1999/02/22-rdf-syntax-ns#predicate> p
.
r.string-value
<http://www.w3.org/1999/02/22-rdf-syntax-ns#object> o
.
r.string-value
<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement> .
Minden adott e lista-elem számára készítünk egy új RDF URI
hivatkozást: u :=
concat("http://www.w3.org/1999/02/22-rdf-syntax-ns#_", e.li-counter), növeljük az
e.li-counter
(listaelem-számláló) tulajdonság értékét eggyel, majd adjuk ki eredményül
u-t.
Ahogy Az RDF alapfogalmai és
absztrakt szintaxisa dokumentum definiálja, van néhány olyan RDF gráf, amelyeket
nem lehet sorosítani (serialize) RDF/XML-ben. Ezek azok, amelyek:
- Olyan tulajdonságneveket használnak, amelyeket nem lehet átalakítani
névtérrel minősített XML nevekre.
- Egy névtérrel minősített XML név (QName) esetén
korlátozva van az alkalmazható legális karakter-konfiguráció, úgy hogy
nem minden tulajdonság URI-jét lehet ilyen nevekre lefordítani. Az RDF
sorosító szoftverek fejlesztőinek ajánlható, hogy úgy bontsák fel az
URI-t egy névtér-névre és egy helyi névre, hogy vágják azt kétfelé az
utolsó XML nem-NCName
karakter után, biztosítva, hogy a név első karaktere betű, vagy egy '_'
karakter legyen. Ha az URI egy nem-NCName
karakterrel végződik, akkor adjon ki egy ilyen hibaüzenetet, vagy
figyelmeztetést, mint pl. "Ez a gráf nem sorosítható RDF/XML-ben".
- Nem megfelelő, fenntartott neveket használnak tulajdonságok
számára.
- Például egy tulajdonság egy olyan URI-vel, mely ütközik valamelyik syntaxTerms produkcióval.
Implementációs megjegyzés (Informatív): Amikor egy RDF
gráfot sorosítunk RDF/XML-ben, és az egy XML Séma adattípust (XSD) tartalmaz,
akkor azt olyan formában kell (SHOULD) írnunk mely nem igényel
whitespace karakter feldolgozást. Az XSD támogatását NEM várja el
sem az RDF, sem az RDF/XML, ez tehát opcionális.
Ha RDF/XML kódot ágyazunk be HTML-be, vagy XHTML-be, ez sok olyan új
elemet és attribútumot hozhat be az ilyen dokumentumokba, amelyek legtöbbje
nem lesz benne az adott DTD-ben. Az ilyen beágyazott kód tehát hibát fog
jelezni, amikor a validáció során ütköztetjük a DTD-vel. Az a kézenfekvőnek
látszó megoldás, azonban, hogy terjesszük ki, vagy cseréljük le a DTD-t, nem
igazán praktikus az alkalmazások egy részénél. Ezt a problémát behatóan
elemezte Sean B. Palmer az RDF
in HTML: Approaches [RDF-IN-XHTML] című
dolgozatában, és arra a megállapításra jutott, hogy nincs olyan közös
beágyazási módszer, mely kielégítené az alkalmazásokat, és mégis egyszerű
maradna.
Az ajánlható közelítés az, hogy ne ágyazzunk be RDF/XML-t a HTML-be vagy
XHTML-be, hanem ehelyett használjunk egy <link> elemet a
különálló RDF/XML dokumentumra, a HTML vagy XHTML dokumentum
<head> elemében. Ezt a módszert már évek óta használja a
saját webhelyén a Dublin Core Metadata
Initiative (DCMI).
Ezt a technikát úgy használjuk, hogy a <link> elem
href attribútumában lévő URI az RDF/XML tartalomra mutat, a
type attribútum pedig az "application/rdf+xml" értéket kapja,
ami az RDF/XML javasolt MIME típusa (lásd a 4.
fejezetben).
A rel attribútum értékét is beállíthatjuk, hogy az a
viszonyt jelölje; ez egy alkalmazásfüggő érték. A DCMI pl. a
rel="meta" értéket használja, a linkhez (RFC 2731 – Encoding Dublin
Core Metadata in HTML – [RFC-2731]), de
a rel="alternate" változat is megfelelő lehet. További
információk találhatók a HTML 4.01 link
types, XHTML
Modularization – LinkTypes és XHTML 2.0
– LinkTypes dokumentumokban azokról az értékekről, amelyek
alkalmasak lehetnek a HTML különböző változataiban.
A 21. példa mutatja ennek a módszernek a
használatát, ahol egy HTML dokumentumban egy link teg csatol be
egy külső RDF/XML dokumentumot.
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>My document</title>
<meta http-equiv="Content-type" content='text/html; charset="utf-8"' />
<link rel="alternate" type="application/rdf+xml" title="RDF Version" href="example21.rdf" />
</head>
<body>
<h1>My document</h1>
</body>
</html>
10
Az RDF/XML használata SVG-vel (Informatív)
Létezik egy szabványosított módszer, amellyel RDF kompatibilis
meta-adatokat kapcsolhatunk SVG-hez. Ez egy olyan meta-adat elem, amelyet
kifejezetten erre a célra terveztek, ahogyan azt a Scalable Vector Graphics
(SVG) 1.0 Specification – [SVG] dokumentum
21. Metadata fejezete,
valamint a Scalable
Vector Graphics (SVG) 1.1 Specification – [SVG11] dokumentum 21. Metadata fejezete
definiálja.
Ez a dokumentum két gráf-példát tartalmaz SVG-ben ilyen beágyazott RDF/XML
kóddal az 1.
ábra és a 2. ábra
meta-adat elemében.
11 Köszönetnyilvánítás (Informatív)
Az alábbi munkatársak értékes hozzájárulását tartalmazza ez a dokumentum:
- Dan Brickley, W3C/ILRT
- Jeremy Carroll, HP Labs, Bristol
- Graham Klyne, Nine by Nine
- Bijan Parsia, MIND Lab at University of Maryland at College Park
Ez a dokumentum az RDF-mag Munkacsoport hosszas megfontolásainak az
eredménye. Ennek a csoportnak a tagjai: Art Barstow (W3C) Dave Beckett
(ILRT), Dan Brickley (W3C/ILRT), Dan Connolly (W3C), Jeremy Carroll (Hewlett
Packard), Ron Daniel (Interwoven Inc), Bill dehOra (InterX), Jos De Roo
(AGFA), Jan Grant (ILRT), Graham Klyne (Clearswift and Nine by Nine), Frank
Manola (MITRE Corporation), Brian McBride (Hewlett Packard), Eric Miller
(W3C), Stephen Petschulat (IBM), Patrick Stickler (Nokia), Aaron Swartz
(HWG), Mike Dean (BBN Technologies / Verizon), R. V. Guha (Alpiri Inc), Pat
Hayes (IHMC), Sergey Melnik (Stanford University), Martyn Horner (Profium
Ltd).
Ez a specifikáció merít egyrészt a korábbi RDF Model and Syntax
dokumentumból, amelyet Ora Lassilla és Ralph Swick szerkesztettek, másrészt
az RDF Séma dokumentumból, amelynek szerkesztői Dan Brickley and R.
V. Guha voltak. Azok az RDF és RDF Séma munkacsoport-tagok, akik munkájukkal
hozzájárultak e korábbi specifikációk létrejöttéhez, a következők voltak:
Nick Arnett (Verity), Tim Berners-Lee (W3C), Tim Bray (Textuality), Dan
Brickley (ILRT / University of Bristol), Walter Chang (Adobe), Sailesh
Chutani (Oracle), Dan Connolly (W3C), Ron Daniel (DATAFUSION), Charles
Frankston (Microsoft), Patrick Gannon (CommerceNet), RV Guha (Epinions,
previously of Netscape Communications), Tom Hill (Apple Computer), Arthur van
Hoff (Marimba), Renato Iannella (DSTC), Sandeep Jain (Oracle), Kevin Jones,
(InterMind), Emiko Kezuka (Digital Vision Laboratories), Joe Lapp (webMethods
Inc.), Ora Lassila (Nokia Research Center), Andrew Layman (Microsoft), Ralph
LeVan (OCLC), John McCarthy (Lawrence Berkeley National Laboratory), Chris
McConnell (Microsoft), Murray Maloney (Grif), Michael Mealling (Network
Solutions), Norbert Mikula (DataChannel), Eric Miller (OCLC), Jim Miller
(W3C, emeritus), Frank Olken (Lawrence Berkeley National Laboratory), Jean
Paoli (Microsoft), Sri Raghavan (Digital/Compaq), Lisa Rein (webMethods
Inc.), Paul Resnick (University of Michigan), Bill Roberts (KnowledgeCite),
Tsuyoshi Sakata (Digital Vision Laboratories), Bob Schloss (IBM), Leon Shklar
(Pencom Web Works), David Singer (IBM), Wei (William) Song (SISU), Neel
Sundaresan (IBM), Ralph Swick (W3C), Naohiko Uramoto (IBM), Charles Wicksteed
(Reuters Ltd.), Misha Wolf (Reuters Ltd.), Lauren Wood (SoftQuad).
12
A hivatkozások listája
Normatív hivatkozások
- [RDF-MS]
- Resource
Description Framework (RDF) Model and Syntax Specification,
O. Lassila and R. Swick, Editors. World Wide Web Consortium. 22
February 1999. This version is
http://www.w3.org/TR/1999/REC-rdf-syntax-19990222. The latest version of RDF
M&S is available at http://www.w3.org/TR/REC-rdf-syntax.
- [XML]
- Extensible
Markup Language (XML) 1.0, Second Edition, T. Bray, J.
Paoli, C.M. Sperberg-McQueen and E. Maler, Editors. World Wide Web
Consortium. 6 October 2000. This version is
http://www.w3.org/TR/2000/REC-xml-20001006. latest version of XML is
available at http://www.w3.org/TR/REC-xml.
- [XML-NS]
- Namespaces in
XML, T. Bray, D. Hollander and A. Layman, Editors. World
Wide Web Consortium. 14 January 1999. This version is
http://www.w3.org/TR/1999/REC-xml-names-19990114. The latest version of Namespaces
in XML is available at http://www.w3.org/TR/REC-xml-names.
- [INFOSET]
- XML
Information Set, J. Cowan and R. Tobin, Editors. World Wide
Web Consortium. 24 October 2001. This version is
http://www.w3.org/TR/2001/REC-xml-infoset-20011024. The latest version of XML
Information set is available at
http://www.w3.org/TR/xml-infoset.
- [URIS]
- RFC 2396
– Uniform Resource Identifiers (URI): Generic Syntax,
T. Berners-Lee, R. Fielding and L. Masinter, IETF, August 1998. This
document is http://www.isi.edu/in-notes/rfc2396.txt.
- [RDF-FOGALMAK]
- Az RDF Erőforrás Leíró
Keretrendszer alapfogalmai és absztrakt szintaxisa, W3C
Ajánlás, 2004. február 10. Szerkesztők: Klyne G., Carroll J. A mindenkori legutolsó (angol
nyelvű) verzió URL-je: http://www.w3.org/TR/rdf-concepts/.
- [RDF-TESZTEK]
- Az RDF
tesztsorozata, W3C Ajánlás, 2004. február 10. Szerkesztők:
Grant J., Beckett D. A
mindenkori legutolsó (angol nyelvű) verzió URL-je:
http://www.w3.org/TR/rdf-testcases/.
- [KEYWORDS]
- RFC 2119 –
Key words for use in RFCs to Indicate Requirement Levels, S.
Bradner, IETF. March 1997. This document is
http://www.ietf.org/rfc/rfc2119.txt.
- [RFC-3023]
- RFC 3023 –
XML Media Types, M. Murata, S. St.Laurent, D.Kohn, IETF.
January 2001. This document is http://www.ietf.org/rfc/rfc3023.txt.
- [IANA-MEDIA-TYPES]
- MIME
Media Types, The Internet Assigned Numbers Authority (IANA).
This document is http://www.iana.org/assignments/media-types/ . The registration
for
application/rdf+xml is archived at
http://www.w3.org/2001/sw/RDFCore/mediatype-registration .
- [XML-BASE]
- XML
Base, J. Marsh, Editor, W3C Recommendation. World Wide Web
Consortium, 27 June 2001. This version of XML Base is
http://www.w3.org/TR/2001/REC-xmlbase-20010627. The latest version of XML Base is
at http://www.w3.org/TR/xmlbase.
- [XML-XC14N]
- Exclusive
XML Canonicalization Version 1.0, J. Boyer, D.E. Eastlake
3rd, J. Reagle, Authors/Editors. W3C Recommendation. World Wide Web
Consortium, 18 July 2002. This version of Exclusive XML
Canonicalization is
http://www.w3.org/TR/2002/REC-xml-exc-c14n-20020718. The latest version of Canonical
XML is at http://www.w3.org/TR/xml-exc-c14n.
- [UNICODE]
- The Unicode Standard, Version 3, The Unicode Consortium,
Addison-Wesley, 2000. ISBN 0-201-61633-5, as updated from time to time
by the publication of new versions. (See http://www.unicode.org/unicode/standard/versions/
for the latest version and additional information on versions of the
standard and of the Unicode Character Database).
- [NFC]
- Unicode
Normalization Forms, Unicode Standard Annex #15, Mark Davis,
Martin Dürst. (See http://www.unicode.org/unicode/reports/tr15/
for the latest version).
Informational References
- [CHARMOD]
- Character Model
for the World Wide Web 1.0, M. Dürst, F. Yergeau, R. Ishida,
M. Wolf, A. Freytag, T Texin, Editors, World Wide Web Consortium
Working Draft, work in progress, 20 February 2002. This version of the
Character Model is http://www.w3.org/TR/2002/WD-charmod-20020220. The
latest version of the Character
Model is at http://www.w3.org/TR/charmod.
- [RDF-SZEMANTIKA]
- Az RDF
Szemantikája, W3C Ajánlás, 2004. február 10. Szerkesztők:
Hayes P. A mindenkori legutolsó
(angol nyelvű) verzió URL-je: http://www.w3.org/TR/rdf-mt/.
- [RDF-BEVEZETÉS]
- Az RDF bevezető
tankönyve, W3C Ajánlás, 2004. február 10. Szerkesztők: Frank
Manola and Eric Miller. A
mindenkori legutolsó (angol nyelvű) verzió URL-je
http://www.w3.org/TR/rdf-primer/ .
- [RDF-SZÓKÉSZLET]
- Az RDF Szókészlet Leíró
Nyelv 1.0: RDF Séma, W3C Ajánlás, 2004. február 10.
Szerkesztők: Brickley D., Guha R.V. A mindenkori legutolsó (angol
nyelvű) verzió URL-je: http://www.w3.org/TR/rdf-schema/.
- [STRIPEDRDF]
- RDF: Understanding
the Striped RDF/XML Syntax, D. Brickley, W3C, 2001. This
document is http://www.w3.org/2001/10/stripes/.
- [SVG]
- Scalable
Vector Graphics (SVG) 1.0 Specification, J. Ferraiolo
(editor), 4 September 2001, W3C Recommendation. This version of SVG is
http://www.w3.org/TR/2001/REC-SVG-20010904. The latest version of SVG is at
http://www.w3.org/TR/SVG.
- [SVG11]
- Scalable Vector
Graphics (SVG) 1.1 Specification, J. Ferraiolo, J. FUJISAWA,
D. Jackson (editors), 14 January 2003, W3C Recommendation. This version
of SVG is http://www.w3.org/TR/2003/REC-SVG11-20030114/. The latest version of SVG is at
http://www.w3.org/TR/SVG11.
- [XPATH]
- XML Path
Language (XPath) Version 1.0, J. Clark and S. DeRose,
Editors. World Wide Web Consortium, 16 November 1999. This version of
XPath is http://www.w3.org/TR/1999/REC-xpath-19991116. The latest version of XPath is at
http://www.w3.org/TR/xpath.
- [SAX2]
- SAX Simple API for XML,
version 2, D. Megginson, SourceForge, 5 May 2000. This
document is http://sax.sourceforge.net/.
- [UNPARSING]
- Unparsing
RDF/XML, J. J. Carroll, HP Labs Technical Report,
HPL-2001-294, 2001. This document is available at
http://www.hpl.hp.com/techreports/2001/HPL-2001-294.html.
- [RELAXNG]
- RELAX
NG Specification, James Clark and MURATA Makoto, Editors,
OASIS Committee Specification, 3 December 2001. This version of
RELAX NG is
http://www.oasis-open.org/committees/relax-ng/spec-20011203.html. The
latest
version of the RELAX NG Specification is at
http://www.oasis-open.org/committees/relax-ng/spec.html.
- [RELAXNG-COMPACT]
- RELAX
NG Compact Syntax, James Clark, Editor. OASIS Committee
Specification, 21 November 2002. This document is
http://www.oasis-open.org/committees/relax-ng/compact-20021121.html.
- [RDF-IN-XHTML]
- RDF in HTML:
Approaches, Sean B. Palmer, 2002
- [RFC-2731]
- RFC 2731 –
Encoding Dublin Core Metadata in HTML, John Kunze, DCMI,
December 1999.
- [XML-SCHEMA1]
- XML Schema
Part 1: Structures, H.S. Thompson, D. Beech, M. Maloney, N.
Mendelsohn, Editors, World Wide Web Consortium Recommendation, 2 May
2001. This version of XML Schema Part 1: Structures is
http://www.w3.org/TR/2001/REC-xmlschema-1-20010502/. The latest version of XML Schema
Part 1: Structures is at http://www.w3.org/TR/xmlschema-1.
- [XML-SCHEMA2]
- XML Schema
Part 2: Datatypes, P.V. Biron, A. Malhotra, Editors, World
Wide Web Consortium Recommendation, 2 May 2001. This version of XML
Schema Part 2: Datatypes is
http://www.w3.org/TR/2001/REC-xmlschema-2-20010502/. The latest version of XML Schema
Part 2: Datatypes is at http://www.w3.org/TR/xmlschema-2.
A. függelék: Szintaxis
sémák (Informatív)
Ez a függelék XML sémákat tartalmaz RDF/XML formák
érvényesség-ellenőrzéséhez (validation). Ezek csak példa sémák tájékoztatási
célokra, és nem képezik a specifikációnk részét.
A.1
függelék: A RELAX NG kompakt szintaxis-séma (Informatív)
Ez egy példa séma az RDF/XML számára RELAX NG Compact
formában (a könnyebb olvashatóság kedvéért). Az alkalmazások használhatják a
RELAX NG
XML version-t is. Ezek a formátumok a RELAX NG
([RELAXNG]) és a RELAX NG
Compact ([RELAXNG-COMPACT]) dokumentumokban
vannak leírva.
Megjegyzés: Az RNGC sémát aktualizálták, hogy
megkíséreljék a nyelvtanhoz igazítani, de ezt nem ellenőrizték, és nem is
használták RDF/XML dokumentumok validációjához.
#
# RELAX NG Compact Schema for RDF/XML Syntax
#
# This schema is for information only and NON-NORMATIVE
#
# It is based on one originally written by James Clark in
# http://lists.w3.org/Archives/Public/www-rdf-comments/2001JulSep/0248.html
# and updated with later changes.
#
namespace local = ""
namespace rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
datatypes xsd = "http://www.w3.org/2001/XMLSchema-datatypes"
start = doc
# I cannot seem to do this in RNGC so they are expanded in-line
# coreSyntaxTerms = rdf:RDF | rdf:ID | rdf:about | rdf:parseType | rdf:resource | rdf:nodeID | rdf:datatype
# syntaxTerms = coreSyntaxTerms | rdf:Description | rdf:li
# oldTerms = rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID
# nodeElementURIs = * - ( coreSyntaxTerms | rdf:li | oldTerms )
# propertyElementURIs = * - ( coreSyntaxTerms | rdf:Description | oldTerms )
# propertyAttributeURIs = * - ( coreSyntaxTerms | rdf:Description | rdf:li | oldTerms )
# Also needed to allow rdf:li on all property element productions
# since we can't capture the rdf:li rewriting to rdf_<n> in relaxng
# Need to add these explicitly
xmllang = attribute xml:lang { text }
xmlbase = attribute xml:base { text }
# and to forbid every other xml:* attribute, element
doc =
RDF | nodeElement
RDF =
element rdf:RDF {
xmllang?, xmlbase?, nodeElementList
}
nodeElementList =
nodeElement*
# Should be something like:
# ws* , ( nodeElement , ws* )*
# but RELAXNG does this by default, ignoring whitespace separating tags.
nodeElement =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype | rdf:li |
rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID ) {
(idAttr | nodeIdAttr | aboutAttr )?, xmllang?, xmlbase?, propertyAttr*, propertyEltList
}
# It is not possible to say "and not things
# beginning with _ in the rdf: namespace" in RELAX NG.
ws =
" "
# Not used in this RELAX NG schema; but should be any legal XML
# whitespace defined by http://www.w3.org/TR/2000/REC-xml-20001006#NT-S
propertyEltList =
propertyElt*
# Should be something like:
# ws* , ( propertyElt , ws* )*
# but RELAXNG does this by default, ignoring whitespace separating tags.
propertyElt =
resourcePropertyElt |
literalPropertyElt |
parseTypeLiteralPropertyElt |
parseTypeResourcePropertyElt |
parseTypeCollectionPropertyElt |
parseTypeOtherPropertyElt |
emptyPropertyElt
resourcePropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
idAttr?, xmllang?, xmlbase?, nodeElement
}
literalPropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
(idAttr | datatypeAttr )?, xmllang?, xmlbase?, text
}
parseTypeLiteralPropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
idAttr?, parseLiteral, xmllang?, xmlbase?, literal
}
parseTypeResourcePropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
idAttr?, parseResource, xmllang?, xmlbase?, propertyEltList
}
parseTypeCollectionPropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
idAttr?, xmllang?, xmlbase?, parseCollection, nodeElementList
}
parseTypeOtherPropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
idAttr?, xmllang?, xmlbase?, parseOther, any
}
emptyPropertyElt =
element * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype |
rdf:Description | rdf:aboutEach | rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
idAttr?, (resourceAttr | nodeIdAttr)?, xmllang?, xmlbase?, propertyAttr*
}
idAttr =
attribute rdf:ID {
IDsymbol
}
nodeIdAttr =
attribute rdf:nodeID {
IDsymbol
}
aboutAttr =
attribute rdf:about {
URI-reference
}
propertyAttr =
attribute * - ( local:* | rdf:RDF | rdf:ID | rdf:about | rdf:parseType |
rdf:resource | rdf:nodeID | rdf:datatype | rdf:li |
rdf:Description | rdf:aboutEach |
rdf:aboutEachPrefix | rdf:bagID |
xml:* ) {
string
}
resourceAttr =
attribute rdf:resource {
URI-reference
}
datatypeAttr =
attribute rdf:datatype {
URI-reference
}
parseLiteral =
attribute rdf:parseType {
"Literal"
}
parseResource =
attribute rdf:parseType {
"Resource"
}
parseCollection =
attribute rdf:parseType {
"Collection"
}
parseOther =
attribute rdf:parseType {
text
}
URI-reference =
string
literal =
any
IDsymbol =
xsd:NMTOKEN
any =
mixed { element * { attribute * { text }*, any }* }
Javítások a 2003.
október 10-i végleges munkaanyag kiadása óta:
Ezeket "szerkesztői" és "nem szerkesztői" javításokra bontva közöljük. A
nem szerkesztői javítások között felsoroljuk a következményszerű javításokat
is. A szerkesztői javítások azok, amelyek nem változtatják meg az RDF
dokumentum jelentését, vagy egy RDF alkalmazás viselkedését.
Nincs
- Német fordítás
- A 2.7 szekcióban, a 8. példa német szövegének javítása Benjamin
Nowack észrevétele alapján.
- Nincsenek tulajdonság-attribútumok a rdf:parseType="Resource"
tulajdonság esetén
- A 2.5 szekciót
aktualizáltuk, hogy tükrözze azt a szintaxis definíciót, hogy
tulajdonság-attribútumok nem használhatók az
rdf:parseType="Resource" esetén, amelyre Sabadello
2003-10-30 keltezésű kommentárja mutatott rá.
- Az URI-k kódolása
- Az 6.1.6, 6.1.8, 6.1.9 szekcióban, Jeremy
Carroll javaslata alapján.
A 6.1.2, 6.1.4 szekciókban új elem/attribútum
URI-string-value akcesszorok.
A 7.2.11, 7.2.21 szekciókban új URI hivatkozás
esemény alkalmazása az rdf:type eseteknél.
A 7.2.11-ben (<e.URI> és
<a.URI>), a 7.2.15-ben
(<e.URI>), a 7.2.16-ban
(<e.URI>), a 7.2.17-ben (<e.URI>), a
7.2.18-ban (<e.URI>),
a 7.2.19-ben
(<e.URI> kétszer), a 7.2.21-ben
(<e.URI> kétszer, <a.URI> egyszer) került megváltoztatásra
X.URI-ról X.URI-string-value formára (bárhol, ahol "<"..">"
jelent meg a nyelvtani akcióban egy fix URI hivatkozással)
A 7.2.32 szekcióban az akció
megfogalmazása "Egy RDF URI hivatkozás"-ra változott.
Minden kijavításra került a 2003-10-06
dátumú javaslatból, Patel-Schneider
2003-10-29-i megjegyzései alapján.
Nincs
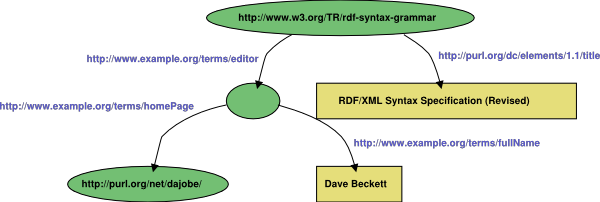
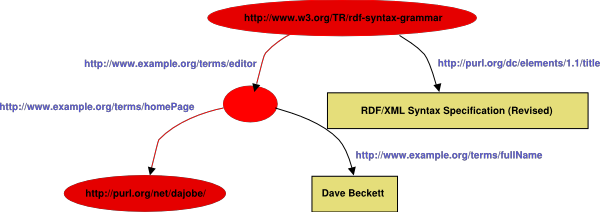
{kind=link}
{kind=link}
{kind=link}
{kind=link}